https://product.kyobobook.co.kr/detail/S000001810160
파이썬 라이브러리를 활용한 데이터 분석 | 웨스 맥키니 - 교보문고
파이썬 라이브러리를 활용한 데이터 분석 | 빅데이터 분석에 관한 가장 완벽한 교재!이 책은 NumPy, pandas, matplotlib, IPython, Jupyter 등 다양한 파이썬 라이브러리를 사용해서 효과적으로 데이터를 분
product.kyobobook.co.kr
Numpy
1. array 배열
- 객체를 받아서 새로운 Numpy 배열을 생성한다.
- 같은 길이의 리스트를 가진 순차 데이터도 다차원 배열로 생성이 가능하다.
- 리스트 보다 배열이 계산 속도가 빠르다.
import numpy as np
#array 함수
data1 = [6., 7., 8., 9.]
arr1 = np.array(data1)
arr1
arr1.dtypearray([6, 7, 8, 9])
dtype('float64')
#리스트 순차 데이터를 다차원 배열로 변환
data2 [[1, 2, 3, 4], [5, 6, 7, 8]]
arr2 = np.array(data2)
arr2array([[1, 2, 3, 4],
[5, 6, 7, 8]])
# 행렬의 행과 열 크기
arr2.ndim
# 행렬의 차원
arr2.shape2
(2, 4)
벡터화: 같은 크기의 배열끼리 산술 연산 처리는 각 원소 단위로 적용한다. 배열은 for 등의 반복문 없이 데이터를 일괄 처리할 수 있다는 장점이 존재한다.
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr
arr * arrarray([[1., 2., 3.],
[4., 5., 6.]])
array([[ 1., 4., 9.],
[16., 25., 36.]])
인덱싱: 데이터의 부분 집합이나 개별 요소를 선택한다.
arr = np.arange(10)
arr
arr[5]
arr[5:8]array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
5
array([5, 6, 7])
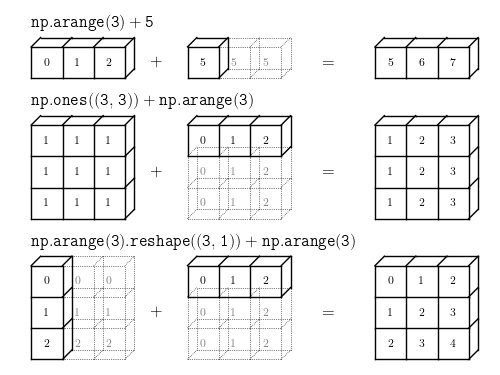
- 배열의 조각에 스칼라 값을 대입하면, 다른 모양의 배열끼리의 연산을 자동으로 크기를 맞춰줘서 요소 단위 연산을 수행하는 브로드캐스팅이 이루어 진다. 리스트에서는 불가능하다.
- slice는 영역을 참조하고 있는 것이므로, 차원이 변하지 않고, 슬라이스 후 값을 변경하면 원본 배열에서도 값이 변한다.
arr[5:8] = 12
arr
arr_slice = arr[5:8]
arr_slice
arr_slice[1] = 123
arr
arr[5:8].copy()array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])
array([12, 12, 12])
array([ 0, 1, 2, 3, 4, 12, 123, 12, 8, 9])
array([12, 123, 12])
2. 다차원 배열
- 2차원 배열의 각 색인에 해당하는 요소들은 스칼라 값이 아닌 1차원 배열이다.
- 2차원 배열에서 인덱싱을 통해 1차원 배열을 가져올 수 있지만 차원이 낮아진다.
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
arr[2]array([7, 8, 9])
개별 요소에 접근하는 방법으로는 재귀적 접근과 색인 리스트 사용이 있다.
#재귀적 접근
arr[0][2]
#콤마로 구분된 색인 리스트 사용
arr2d[0, 2]3
3

old_values = arr[0].copy()
# 스칼라 값 대입
arr[0] = 42
arrarray([[0, 0, 0], [4, 5, 6], [7, 8, 9]])
3. 2차원배열의 슬라이싱

슬라이싱은 배열에서 일부 요소를 추출하는 기능이다. 콜론 : 으로 시작 인덱스와 끝 인덱스를 지정하고 콤마 , 로 다차원 배열에서 각 차원의 슬라이스를 지정할 수 있다.
4. 불리언 배열
중복된 이름이 포함된 배열과 randn 함수(numpy.random모듈)를 사용해서 임의의 표준 정규 분포 데이터 생성한다.
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
data = np.random.randn(7, 4)
names
dataarray(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
array([[-0.7206, 0.8872, 0.8596, -0.6365],
[ 0.0157, -2.2427, 1.15 , 0.9919],
[ 0.9533, -2.0213, -0.3341, 0.0021],
[ 0.4055, 0.2891, 1.3212, -1.5469],
[-0.2026, -0.656 , 0.1934, 0.5534],
[ 1.3182, -0.4693, 0.6756, -1.817 ],
[-0.1831, 1.059 , -0.3978, 0.3374]])
# 산술연산과 같이 배열에 대한 비교 연산도 벡터화됨
# names를 Bob 문자열과 비교하면 불리언 배열을 반환
names == 'Bob'array([ True, False, False, True, False, False, False])
불리언 배열 메서드
arr = np.random.randn(100)
( arr > 0 ).sum(0) # 양수인 원소의 개수49
- all: 모든 원소가 True인지 판단한다.
- any: 하나 이상의 값이 True인지 판단한다.
bools = np.array([False, False, True, False])
bools.any()
bools.all()True
False
5. 정수 배열을 사용해서 색인하는 팬시 인덱싱
arr = np.empty((8, 4))
for i in range(8):
arr[i] = i
arrarray([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
arr[[-3, -5, -7]]array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])
(1,0), (5,3), (7, 1), (2, 2)에 대응하는 원소들을 선택하는 방법이다. 배열이 차원과 상관없이 팬시 색인의 결과는 항상 1 차원이다.
arr = np.arange(32).reshape((8, 4))
arr
arr[[1, 5, 7, 2], [0, 3, 1, 2]]
arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
array([ 4, 23, 29, 10])
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
6. 배열 전치
- 배열 전치는 데이터를 복사하지 않고 데이터의 모양이 바뀐 출력을 변환하는 기능이다.
- 기존 배열의 행과 열을 교환하여 새로운 배열을 반환한다.
arr = np.arange(15).reshape((3,5))
arr
arr.Tarray([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
arr = np.random.randn(6, 3)
np.dot(arr.T, arr)
# 전치로 인해서 3행 6열이 된 것과 내적
np.transpose(arr)
arr.swapaxes(0, 1)array([[2.2033, 2.8639, 2.1538],
[2.8639, 8.2031, 1.2557],
[2.1538, 1.2557, 5.2266]])
array([[ 1.0476, -0.1221, 0.8417, -0.5664, 0.2478, 0.0183],
[ 1.0459, 0.1247, 2.391 , 0.0361, -0.8972, 0.7554],
[ 0.8637, -0.3228, 0.0762, -2.075 , -0.1368, 0.2153]])
array([[ 1.0476, -0.1221, 0.8417, -0.5664, 0.2478, 0.0183],
[ 1.0459, 0.1247, 2.391 , 0.0361, -0.8972, 0.7554],
[ 0.8637, -0.3228, 0.0762, -2.075 , -0.1368, 0.2153]])
7. 유니버셜 함수
ufunc은 유니버셜 함수로서 ndarray 안에 있는 데이터 원소별로 연산을 수행하는 함수이다.
x = np.random.randn(8)
y = np.random.randn(8)
np.maximum(x, y)
# 각 배열의 같은 항,열에 있는 원소끼리 비교해서 큰 값을 반환array([ 0.841 , 1.5457, -0.9742, -0.0703, 0.308 , -0.1446, 1.0338, -0.0355])
arr = np.random.randn(7) * 5
np.modf(arr)
remainder, whole_part = np.modf(arr)
remainder
# 나머지 값을 remainder에 저장하고, 몫을 whole_part에 저장
whole_part(array([ 0.153 , -0.7132, 0.0594, 0.5236, -0.9272, 0.3103, 0.5211]),
array([10., -5., 1., 3., -3., 2., 3.]))
array([ 0.153 , -0.7132, 0.0594, 0.5236, -0.9272, 0.3103, 0.5211])
array([10., -5., 1., 3., -3., 2., 3.])


[예제] np.where 사용법
arr = np.random.randn(4, 4)
arrarray([[ 0.5235, -0.9263, 2.0078, 0.227 ],
[-1.1527, 0.632 , 0.0395, 0.4644],
[-3.5635, 1.3211, 0.1526, 0.1645],
[-0.4301, 0.7674, 0.9849, 0.2708]])
np.where(arr > 0, 2, -2)
# 양수인 경우에만 2를 대입rray([[ 2, -2, 2, 2],
[-2, 2, 2, 2],
[-2, 2, 2, 2],
[-2, 2, 2, 2]])
8. 수학, 통계 메서드
- 배열 전체나 축을 따르는 자료의 통계를 내는 수학 함수는 배열 메서드로 사용한다.
- 합 sum, 평균 mean, 표준편자 std 등의 계산은 Numpy의 최상위 함수를 이용하거나 배열 인스턴스 메서드를 사용한다.
arr = np.random.randn(5, 4)
arr
# 배열의 인스턴스 메서드
arr.mean()
#Numpy의 최상위 함수
np.mean(arr)array([[ 0.77675471, -1.21334886, 0.72551611, 1.06066406],
[-0.10930301, -0.13890227, 1.70078279, -0.95959713],
[ 1.3129549 , 1.6504395 , -0.20319363, 0.81423818],
[-0.14536605, 0.09525325, 0.37161845, -0.04910358],
[-0.66407129, 0.72803728, 0.42240622, -1.36516873]])
-0.18106372261119644
-0.18106372261119644
# 축방향으로 계산
arr.max(axis=1)array([0.54891331, 1.70512175, 0.90191488, 2.10948425, 1.03309738])
cumsum: 누적 합의 중간 계산 값을 연산해주는 함수이다. 다차원 배열에서 같은 크기의 배열을 반환한다.
arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
arr1 = arr.cumsum(axis=0)
arr1
arr2 = arr.cumprod(axis=1)
arr2array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]])
array([[ 0, 0, 0],
[ 3, 12, 60],
[ 6, 42, 336]])


9. 정렬
- np.sort(arr): 배열을 직접 변경하기 않고 정렬된 결과를 가지고 있는 복사본을 출력한다.
- arr.sort(): 원래의 배열 자체를 정렬한다.
arr = np.random.randn(5, 3)
# Axis = 0
arr.sort(0)
arr
# Axis = 1
arr.sort(1)
arrarray([[-0.62 , -1.0515, -0.5715],
[-0.4315, -0.7915, -0.5246],
[ 0.0719, -0.1611, -0.3196],
[ 0.2884, 0.157 , 0.788 ],
[ 1.0576, 1.9108, 0.8892]])
array([[-1.0515, -0.62 , -0.5715],
[-0.7915, -0.5246, -0.4315],
[-0.3196, -0.1611, 0.0719],
[ 0.157 , 0.2884, 0.788 ],
[ 0.8892, 1.0576, 1.9108]])
- unique: 배열 내에서 중복된 원소를 제거하고 원소를 정렬시킨다.
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
np.unique(names)array(['Bob', 'Joe', 'Will'], dtype='<U4')
- in1d: 첫 번째 배열의 원소가 두 번째 배열의 원소를 포함하는지 나타내는 불리언 배열을 반환한다.
values = np.array([6, 0, 0, 3, 2, 5, 6])
np.in1d(values, [2, 3, 6])array([ True, False, False, True, True, False, True])
10. 난수 생성
random은 다양한 종류의 확률 분포로부터 효과적으로 난수 표본값을 생성한다. 난수 생성기의 시드값에 따라 알고리즘으로 정해진 난수를 생성해서 완벽하게 무작위를 구현할 수 있는 것은 아니다.
from random import normalvariate
N = 1000000
# 한번에 하나의 값만을 생성
%timeit samples = [normalvariate(0, 1)]
%timeit np.random.normal(size=N)784 ns ± 24.4 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
44.8 ms ± 8.79 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# 시드 값을 설정
np.random.seed(1234)
# 무작위 값 시퀀스를 생성
r1 = np.random.random(size = 4)
r1array([0.1915, 0.6221, 0.4377, 0.7854])
rng3 = np.random.RandomState(5)
rng3.randn(10)array([ 0.4412, -0.3309, 2.4308, -0.2521, 0.1096, 1.5825, -0.9092, -0.5916, 0.1876, -0.3299])
함수 정리
| 함수 | 설명 |
| array | 입력 데이터(리스트, 튜플, 배열 또는 다른 순차형 데이터)를 다차원 배열로 변환하여 기본적으로 입력 데이터를 복사 |
| arr.shape | 행렬의 행, 열 크기 |
| arr.ndim | 행렬의 차원 |
| arr.dtype | 배열의 데이터 타입 |
| np.zeros() | 0으로 초기화된 배열 생성 |
| mp.ones() | 1로 초기화된 배열 생성 |
| np.empty() | 초기화 되지 않은 배열 생성 |
| astype | 배열의 데이터 타입 변경 |
| arr.copy() | 배열을 복사 |
| != 또는 ~ | 일치하지 않는 조건을 추가 |
| np.arange().reshape() | 기존 배열의 요소 개수와 새로운 배열의 요소 개수가 같을 경우 배열의 모양을 변경 |
| np.arange | 0부터 지정한 크기만큼의 숫자들을 배열 형태로 반환 |
| ndarray.T 또는 ndarray.swapaxes(0, 1) np.transpose(ndarray) 또는 np.swapaxes(ndarray, 0, 1) | 데이터를 복사하지 않고 배열의 행과 열을 교환하여 새로운 배열을 생성 |
| np.dot(arr1, arr2) | 배열의 내적 계산` |
| np.where(조건, True일 때 대입값, False일 때 대입값) | list comprehension처럼 한줄에 작성하는 조건문으로 조건에 따른 새로운 배열 생성 |
| np.mean(array) 또는 array.mean() | 배열의 평균을 계산. 축 방향을 지정하면, 방향에 따른 각각의 축에 대해 계산을 출력 |
| np.max(arr) 또는 arr.max() | 배열의 최고값 |
| np.sum(arr) 또는 arr.sum() | 배열의 합 |
| np.std(arr) 또는 arr.std() | 배열의 표준편차 |
| arr.cumsum() | 배열의 누적합 |
| arr.cumprod() | 배열의 누적곱 |
| arr.any() | 하나 이상의 원소가 True인지 검사 |
| arr.all() | 모든 원소가 True인지 검사 |
| np.sort(arr) | 정렬한 배열 복사본 출력 |
| arr.sort() | 배열을 정렬 |
| np.unique(arr) | 배열의 중보된 원소를 제거하고 정렬해서 출력 |
| np.in1d(arr1, arr2) | 첫 번째 배열의 원소에서 두 번째 배열의 원소가 있는지 판단하는 불리언 배열을 출력 |
| np.random.normal(size) | 지정한 크기에 따른 정규 분포에서 난수 표본을 추출해서 배열 생성 |
| np.random.RandomState() | 다른 난수 생성기로부터 격리된 난수 생성기를 만듦 |
| np.random.randn(size) | 지정한 크기에 따른 표준편차가 1이고 평균값이 0인 정규분포에서 난수 표본을 추출하여 배열 생성 |
'일상 > 컴퓨터' 카테고리의 다른 글
| [GitHub 깃 & 깃허브 입문] VS code로 다루기 (0) | 2023.05.05 |
|---|---|
| [Python 파이썬] Pnadas 판다스 기본 (0) | 2023.04.26 |
| [GitHub 깃 & 깃허브 입문] 깃허브로 협업하기 (0) | 2023.04.14 |
| [GitHub 깃 & 깃허브 입문] 협업 환경 (0) | 2023.04.07 |
| [GitHub 깃 & 깃허브 입문] 깃허브 (0) | 2023.03.31 |