Pandas
1. 데이터 자료 구조

Series: 일련의 객체를 담을 수 있는 1차원 배열 형태이다. 인덱스를 부여하지 않으면 자동으로 정수 인덱스가 부여가 된다.
Data frame: Seriese가 합쳐진 것으로, 스프레드 시트 형식으로 여러 개의 열(columns)으로 구성되어 있어서 행과 열의 색인이 가능하다. 원하는 index를 지정할 수 있으며, 지정하지 않으면 자동으로 생성된다.
# 딕셔너리로 Series 생성
sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000}
obj3 = pd.Series(sdata)
obj3
# 키가 인덱스가 되고, 밸류가 Series의 밸류값이 됨Ohio 35000
Texas 71000
Oregon 16000
Utah 5000
dtype: int64
import pandas as pd
import numpy as np
data = {'char': ['A', 'B', 'C'],
'digit': [1, 2, 3, ]}
frame1 = pd.DataFrame(data, index = ['a','b','c'])
frame1| char | digit | |
| a | A | 1 |
| b | B | 2 |
| c | C | 3 |
data2 = [['A', 1], ['B', 2], ['C', 3]]
frame2 = pd.DataFrame(data2, index = ['a','b','c'], columns=[ 'char','digit'])
frame2| char | digit | |
| a | A | 1 |
| b | B | 2 |
| c | C | 3 |
char = ['A', 'B', 'C']
#char = pd.Series(['A', 'B', 'C'], index = ['a','b','c'])
digit = pd.Series([1, 2, 3, ], index = ['a','b','c'])
frame3 = pd.DataFrame(char, index = ['a','b','c'], columns=['char'])
print(frame3)
frame3['digit'] = digit
frame3| char | |
| a | A |
| b | B |
| c | C |
| char | digit | |
| a | A | 1 |
| b | B | 2 |
| c | C | 3 |
#print(frame2.values)
print(frame2.iloc[:,0])
a = frame2.iloc[:,0]
print(type(a))a A
b B
c C
Name: char, dtype: object
<class 'pandas.cor.series.Series'>
- Numpy의 산술 함수 적용이 가능합니다.
- Series는 길이가 고정된 딕셔너리 개념입니다.
2. 인덱스 객체(Index objects)
- Pandas의 색인 객체는 표 형식의 데이터에서 각 로우와 컬럼에 대한 이름과 축의 이름 등의 다른 메타데이터를 저장하는 객체입니다.
- Pandas의 인덱스는 중복된 값을 허용하므로 중복된 값을 선택하게 되면, 해당 값을 가진 모든 항목을 선택하게 되는 것입니다.
obj = pd.Series(range(3), index=['a', 'b', 'c'])
index = obj.index
indexIndex(['a', 'b', 'c'], dtype='object')
obj2 = pd.Series([1.5, -2.5, 0], index=labels)
obj2Int64Index([0, 1, 2], dtype='int64')
- 인덱스(Index) 객체의 drop 또는 delete 함수는 원본 인덱스 객체를 수정하는 것이 아니라, 삭제된 새로운 인덱스 객체를 출력해줍니다.
- 따라서 Pandas의 인덱스(Index) 객체는 변경 불가능(immutable)한 자료형입니다.
dup_labels = pd.Index(['foo', 'bar', 'foo', 'bar'])
dup_labels.delete(1)
dup_labels.drop('bar')
dup_labelsIndex(['foo', 'foo', 'bar'], dtype='object')
Index(['foo', 'foo'], dtype='object')
Index(['foo', 'bar', 'foo', 'bar'], dtype='object')
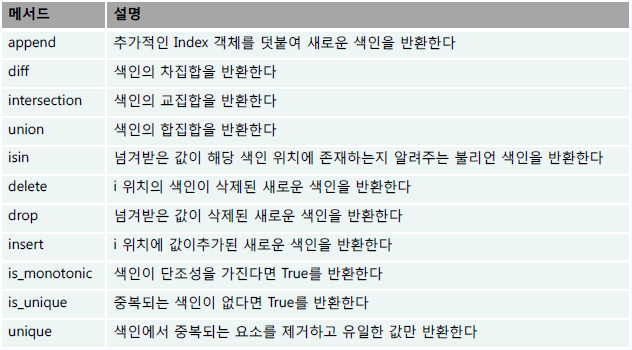
3. 재색인 Reindexing
reindex: 새로운 색인에 맞도록 객체를 새로 생성해서 데이터를 새로운 색인에 맞게 재배열합니다. 동시에 존재하지 않는 색인값은 NaN 추가합니다.
[method 옵션: ffill 사용하기]
obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
obj3
obj3.reindex(range(6), method='ffill')0 blue
2 purple
4 yellow
dtype: object
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object
4. 행이나 열 삭제하기
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.drop(['two', 'four'], axis='columns')
data
one three Ohio 0 2 Colorado 4 6 Utah 8 10 New York 12 14
one two three four Ohio 0 1 2 3 Colorado 4 5 6 7 Utah 8 9 10 11 New york 12 13 14 15
- inplace 옵션: 버려지는 값을 모두 삭제함으로써, Series 나 DataFrame 의 크기 또는 형태를 변경해 새로운 객체를 반환하는 대신 원본 객체를 변경합니다.
obj = pd.Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
obj.drop('c', inplace=True)
obj
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
5. Indexing, Selection, Filtering
# 문자 슬라이싱
obj['b':'c']b 1.0
c 2.0
dtype: float64
obj['b':'c'] = 5
obja 0.0
b 5.0
c 5.0
d 3.0
dtype: float64
# 색인
data[['three', 'one']]| three | one | |
| Ohio | 2 | 0 |
| Colorado | 6 | 4 |
| Utah | 10 | 8 |
| New York | 14 | 12 |
# 불리언 배열로 로우 선택
data['three'] > 5
data[data['three'] > 5]Ohio False
Colorado True
Utah True
New York True
Name: three, dtype: bool
| one | two | three | four | |
| Colorado | 4 | 5 | 6 | 7 |
| Utah | 8 | 9 | 10 | 11 |
| New york | 12 | 13 | 14 | 15 |
6. 정수 인덱스 VS 레이블 인덱스
- loc: 인덱스 레이블을 기반으로 데이터를 축의 이름으로 선택합니다.
- iloc: 정수 위치 인덱스를 기반으로 데이터를 정수 색인으로 선택합니다.
data.loc['Colorado', ['two', 'three']]
# loc를 사용하면 문자 인덱스를 사용할 수 있음two 5
three 6
Name: Colorado, dtype: int64
data.iloc[2, [3, 0, 1]]
# 자동적으로 배정되는 인덱스가 아닌 정수 인덱스임을 표시four 11
one 8
two 9
Name: Utah, dtype: int64
data.iat[1, 1]
# 하나의 칸 위치를 지정할 때 사용5
obj = pd.Series([4, 7, -5, 3])
obj.loc[:2]0 4
1 7
2 -5
dtype: int64
obj.iloc[1]-5
# 에러 발생
obj.loc[1]# ser2라는 정수 기반의 색인이 아닌 시리즈 객체를 하나 만들어서, 위치 기반의 인덱스로 찾는 것을 확인
ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c'])
ser2[-1]2.0
7. 산술 연산
- 판다스는 다른 색인을 가지고 있는 객체 간의 산술 연산이 가능합니다.
- 객체 연산 시에 짝이 맞지 않는 색인이 있다면 두 색인을 통합해서 결과를 냅니다.
- 서로 겹치는 색인이 없는 경우 데이터는NaN이 됩니다.
s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],index=['a', 'c', 'e', 'f', 'g'])
s1 + s2
# NaN 값을 더하면 결과 또한 NaN 값으로 출력됨a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
- fill values: add 메서드와 함께 속성을 사용하면 NaN값을 특정 값으로 채운 후 연산을 실행시킬 수 있습니다.
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
columns=list('abcde'))
df1.add(df2, fill_value=1)| a | b | c | d | e | |
| 0 | 0.0 | 2.0 | 4.0 | 6.0 | 50.0 |
| 1 | 9.0 | 6.0 | 13.0 | 15.0 | 10.0 |
| 2 | 18.0 | 20.0 | 22.0 | 24.0 | 15.0 |
| 3 | 16.0 | 17.0 | 18.0 | 19.0 | 20.0 |
| 연산 | 메소드 | 역연산 메소드 |
| 덧셈(+) | add | radd |
| 뺄셈(-) | sub | rsub |
| 나눗셈(/) | div | rdiv |
| 몫(%) | floordiv | rfloordiv |
| 곱셈(*) | mul | rmul |
| 거듭제곱(**) | pow | rpow |
1 / df1
df1.rdiv(1)| a | b | c | d | |
| 0 | inf | 1.000000 | 0.500000 | 0.333333 |
| 1 | 0.250 | 0.200000 | 0.166667 | 0.142857 |
| 2 | 0.125 | 0.111111 | 0.100000 | 0.090909 |
8. 함수 적용과 매핑

# f는 Series의 최대값과 최소값의 차이를 계산하는 람다 함수
# 람다 함수: 이름이 없는 간단한 함수
f = lambda x: x.max() - x.min()
# 각 열에 대해 한번만 수행
frame.apply(f)b 1.802165
d 1.684034
e 2.689627
dtype: float64
format = lambda x: '%.2f' % x
frame.applymap(format)
frame['e'].map(format)Utah -0.52
Ohio 1.39
Texas 0.77
Oregon -1.30
Name: e, dtype: object
9. 정렬과 순위
- sort_index : 로우나 컬럼의 색인을 알파벳순으로 정렬한 새로운 객체를 반환합니다.
- Series에서는 색인으로 정렬
- DataFrame에서는 axis 속성을 지정할 수 있습니다. 0은 로우의 색인으로 정렬하고, 1은 컬럼의 색인으로 정렬합니다. 기본적으로 로우 색인으로 설정되어 있습니다.
- ascending 속성으로 True을 사용하면 오름차순 정렬이고, False은 내림차순 정렬입니다.
obj = pd.Series(range(4), index=['d', 'a', 'b', 'c'])
obj.sort_index() # 앞의 row index를 abcd 알파벳 순서로 정렬a 1
b 2
c 3
d 0
dtype: int64
frame.sort_index(axis=1, ascending=False) # false 값을 넣어주면 내림차순으로 정렬
- sort_values : 로우나 컬럼의 값을 알파벳순으로 정렬한 새로운 객체를 출력합니다.
- Series에서는 정렬할 때 비어있는 값은 기본적으로 가장 마지막에 위치하게 됩니다.
- DataFrame에서는 by 옵션으로 하나 이상의 컬럼에 있는 값으로 정렬합니다. 컬럼 리스트를 전달할 때는 정렬 우선순위에 따라 리스트를 전달합니다.
obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])
obj.sort_values() # NaN 값은 후순위로 정렬4 -3.0
5 2.0
0 4.0
2 7.0
1 NaN
3 NaN
dtype: float64
frame.sort_values(by=['a', 'b']) # a를 기준으로 먼저 정렬하고, 그 다음 b를 기준으로 정렬
- rank: 데이터의 순위를 부여합니다.
- 1 부터 배열의 유효한 데이터 개수까지 순서를 매기게 됩니다.
- 기본적으로 동점인 항목에는 평균순위를 부여합니다.
| 메서드 | 설명 |
| 'average' | 기본값. 같은 값을 가지는 항목들의 평균값을 순위로 정함 |
| 'min' | 같은 값을 가지는 그룹을 낮은 순위로 정함 |
| 'max' | 같은 값을 가지는 그룹을 높은 순위로 정함 |
| 'first' | 데이터 내의 위치에 따라 순위를 정함 |
| 'dense' | method = 'min'과 같지만 그룹 내에서 모두 같은 순위를 적용하지 않고 1씩 증가 |
obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
obj.rank()
# 동률인 경우 그룹내에서 높은 값의 순위를 적용
obj.rank(ascending=False, method='max') # 내림차순으로 정렬, 동률이 있는 경우, 낮은 순위로 취하게 함
# 제일 높은 7의 값이 2개이므로 1등이 아닌 같이 2등으로 정해짐0 6.5
1 1.0
2 6.5
3 4.5
4 3.0
5 2.0
6 4.5
dtype: float64
0 2.0
1 7.0
2 2.0
3 4.0
4 5.0
5 6.0
6 4.0
dtype: float64
10. 통계 계산과 요약

- axis 옵션으로 연산을 수행할 축을 설정할 수 있으며 DataFrame에서 0 은 로우 1은 컬럼입니다. 기본값은 0입니다.
- skipna 옵션으로 누락된 값을 제외할 것인지 정할 수 있으며, 기본값은 True입니다.
df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5],
[np.nan, np.nan], [0.75, -1.3]],
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
df.sum()
df.sum(axis='columns')
df.sum(axis='columns', skipna = False)one 9.25
two -5.80
dtype: float64
a 1.40
b 2.60
c 0.00
d -0.55
dtype: float64
a NaN
b 2.60
c NaN
d -0.55
dtype: float64
# idxmax, idxmin: 메서드는 최솟값 혹은 최댓값을 가지고 있는 색인값
df.idxmax()
# quantile: 0부터 1까지의 분위수를 계산
# 50%의 값
df.quantile(0.5)
# cumsum: Series 또는 Dataframe의 축을 따라 누적합을 적용
df.cumsum()
# describe: Series 또는 Dataframe의 통계 요약을 반환
df.describe()one b
two d
dtype: object
one 1.4
two -2.9
Name: 0.5, dtype: float64


| 메서드 | 설명 |
| count | NA 값을 제외한 값의 수를 반환 |
| describe | Series나 DataFrame의 각 컬럼에 대한 요약 통계를 계산 |
| min, max | 최솟값과 쵀댓값을 계산 |
| idmin, dimax | 각각 최솟값과 최댓값을 담고 있는 색인의 값을 반환 |
| quantile | 0부터 1까지의 분위수를 계산 |
| sum | 합을 계산 |
| mean | 평균을 계산 |
| median | 중간값(50% 분위)을 반환 |
| mad | 평균값에게 평균절대편차를 계산 |
| prod | 모든 값의 곱 |
| var | 표본분산의 값을 계산 |
| std | 표본표준편차의 값을 계산 |
| skew | 표본비대칭도(3차 적률)의 값을 계산 |
| kurt | 표본첨도(4차 적률)의 값을 계산 |
| cumsum | 누적합을 계산 |
| cummin. cummax | 각각 누적 최솟값과 누적 최댓값을 계산 |
| cumprod | 누적곱을 계산 |
| diff | 1차 산술치를 계산(시계열 데잍 처리 시 유용 |
| pct_change | 퍼센트 변화율을 계산 |
함수 정리
| 함수 | 설명 |
| pd.ser() | 데이터로 Series 객체 생성 |
| ser.value 또는 df.values | 객체의 배열 |
| ser.index | Series의 색인 |
| pd.isnull(series) 또는 ser.isnull() | series의 각각의 배열이 null인지 아닌지 판단 |
| ser.name 또는 df.name | 객체에 name 부여. index를 추가하면 인덱스의 name 생성 가능 |
| df.head() | 상위 5개의 항목 출력 |
| del df['column'] | 열을 삭제 |
| index.delete() 또는 index.drop() | 인덱스를 삭제한 값을 출력 |
| ser.reindex(range(), method='ffill') | 기존의 존재하는 배열의 값을 밀어넣기 |
| df.drop('low' 또는 'column', inplace=True) | 행이나 열을 삭제. inplace 옵션은 버려지는 값을 모두 삭제해서 원본 객체를 변경 |
| df.loc['index'] | 축의 이름을 이용해서 인덱스 레이블을 기반으로 데이터를 선택 |
| df.iloc[1] | 정수 위치 인덱스를 기반으로 데이터를 정수 색인 선택 |
| df.iat[i, j] | 로우와 컬럼의 정수 색인으로 단일 값을 선택 |
| df1.add(df2, fill_value=1) | df1과 df2의 연산시에 NaN 값을 1로 채운 후 덧셈 |
| df.apply(f) | 각 행이나 열의 1차원 배열에 함수를 적용 |
| df.applymap(f) | 각 원소에 함수를 적용 |
| ser['column'].map(f) | series 객체의 원소 마다 함수 적용 |
| ser.rank() 또는 df.rank() | 객체 원소에 순위 매김 |
| ser.index.is_unique | 객체가 unique한지 판단 |
| df.sum(axis='columns', skipna = False) | 객체 합산 시에 축 옵션과 NaN 값을 스킵할지 안 할지 적용 |
반응형
'일상 > 컴퓨터' 카테고리의 다른 글
| [GitHub 깃 & 깃허브 입문] 깃허브를 포트폴리오로 (0) | 2023.05.13 |
|---|---|
| [GitHub 깃 & 깃허브 입문] VS code로 다루기 (0) | 2023.05.05 |
| [Python 파이썬] Numpy 넘파이 기본 (0) | 2023.04.26 |
| [GitHub 깃 & 깃허브 입문] 깃허브로 협업하기 (0) | 2023.04.14 |
| [GitHub 깃 & 깃허브 입문] 협업 환경 (0) | 2023.04.07 |