
최근 AI의 발달로 많은 작업을 AI가 처리할 수 있게 됐다. 그중에서도 이미지 생성은 저작권 문제, 딥페이크 등의 문제가 많지만 이미지 편집이나 그림을 잘 못그리는 사람도 쉽게 원하는 사진을 얻을 수 있다는 장점이 있다. GAN, VAE 등 여러 모델이 있지만 그중에서도 가장 고품질의 다양한 이미지를 생성할 수 있어서 많이 사용하는 Diffusion 모델 계열의 Stable diffusion 모델에 대한 논문을 리뷰해보고자 한다.
논문 출처: https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org
https://ieeexplore-ieee-org-ssl.access.ewha.ac.kr/document/9878449
N2 OpenLink User Authentication
access.ewha.ac.kr
0. Diffusion Model이란?

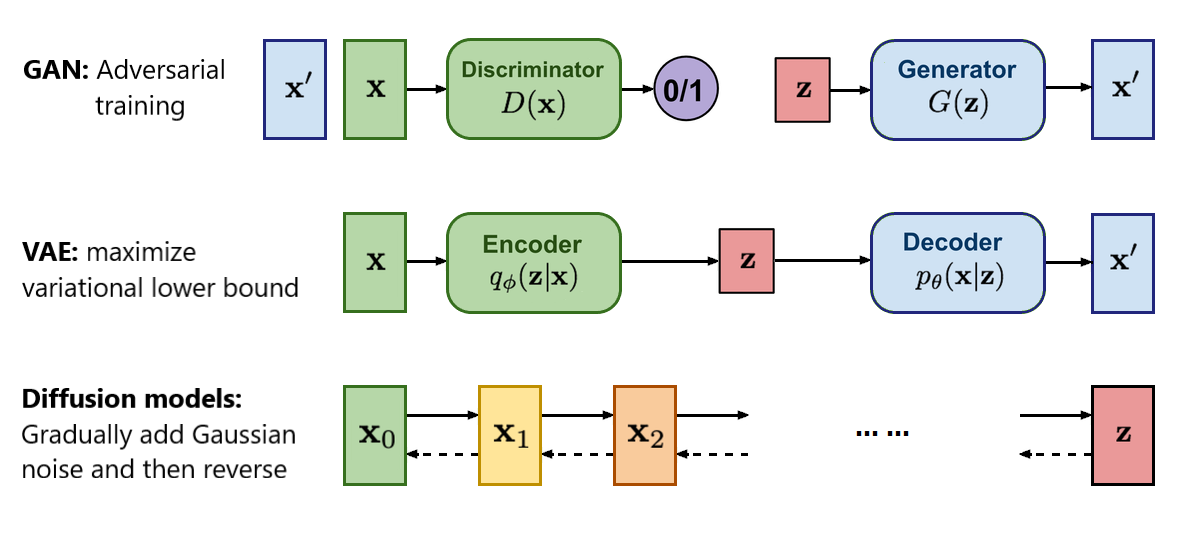
stable diffusion 논문 리뷰 전에 먼저 Diffusion 모델에 대해 짧게 설명하고자 한다. GAN은 생성자와 감시자가 쌍을 이루어서 object fuction을 통해 실제 이미지와 유사하게 만들고자 노력하고, VAE는 인코더 디코더 구조를 이루어서 이미지를 생성하는 모델이다. Difussion 모델은 원본 이미지에서 가우시안 분포의 노이즈를 조금씩 추가하다가 디노이즈를 해서 다시 원본 이미지로 원복시키는 과정을 학습한다. 이 세 모델은 대표적인 생성 모델들이며 그중에서도 difussion 모델은 고품질의 다양한 이미지를 생성할 수 있다는 장점이 있다.

diffusion 모델이 학습하는 과정을 하나의 그림으로 표현하면 foward 과정에서는 원본 이미지 분포를 점점 가우시안 정규 분포의 노이즈 이미지 사진으로 만든 다음에서 완전한 노이즈 사진에서 다시 원본 이미지 분포로 만드는 것이다. 이 과정에서 노이즈에서 이미지를 생성하는 방법을 학습하게 된다.

하지만 노이즈를 조금씩 단계별로 처리해야하기 때문에 생성 속도가 빠르지는 않다는 단점이 있다.
1. Introduction
컴퓨터 비전 분야에서 이미지 생성은 많은 연구자들이 오랫동안 탐구해 온 주제다. 특히, 고해상도 이미지 생성을 위한 기술이 중요하다. 예를 들어, 영화 산업에서 고해상도 이미지 생성은 특수 효과 제작에 필수적이며, 의료 영상 분석에서도 고해상도 이미지를 활용하여 진단의 정확도를 높일 수 있다.
기존의 이미지 생성 기술 중에서 GAN(Generative Adversarial Networks)은 특히 높은 품질의 이미지를 생성할 수 있는 도구로 인기를 끌었다. 하지만 GAN은 훈련 과정에서 발생하는 불안정성, 복잡한 데이터 분포를 제대로 모델링하지 못하는 문제, 그리고 자주 발생하는 모드 붕괴(mode collapse) 등의 한계가 있었다.
이러한 배경에서 등장한 확산 모델(Diffusion Models, DM) Denoising Diffusion Probabilistic Models (DDPMs)은 GAN의 단점을 보완할 수 있는 대안으로 주목받았다. 확산 모델은 이미지 생성 과정을 점진적인 디노이징(denoising) 과정을 통해 수행함으로써 이미지의 고유한 구조를 보다 잘 보존할 수 있게 해준다. 그러나 이러한 모델이 일반적으로 픽셀 공간에서 직접 작동하기 때문에 강력한 DMs의 최적화는 수백 일에 달하는 GPU 시간을 소모하고, 순차적인 평가로 인해 추론 비용이 비싸다는 단점이 존재한다. 제한된 계산 자원에서 DM 훈련을 가능하게 하면서 품질과 유연성을 유지하기 위해, 강력한 사전 학습된 자동 인코더의 잠재 공간에서 이를 적용하였다.
이 논문에서는 이러한 문제를 해결하기 위해 잠재 확산 모델(Latent Diffusion Models, LDMs)을 제안한다. LDM은 고해상도 이미지 생성을 위해 픽셀 공간이 아닌 잠재 공간(latent space)에서 확산 모델을 훈련함으로써 연산 효율성을 극대화하고자 한다.
2. Democratizing High-Resolution Image Synthesis
DMs의 문제점
- 이런 모델을 훈련하기 위해서는 엄청난 계산 자원이 필요하며, 이는 연구 커뮤니티의 일부만 접근 가능하게 한다. 또한, 과도한 탄소 발생이 유도된다.
- 이미 훈련된 모델을 평가하는 것조차 시간과 메모리가 많이 소모된다. 모델 아키텍처를 여러 단계로 순차적으로 실행해야 하기 때문이다.
Departure To Latent Space

먼저 픽셀 공간에서 이미 훈련된 DM을 분석하는 것에서 출발했다. 그림은 훈련된 모델의 비율-왜곡(Rate-Distortion) 트레이드오프 분석이며, 가능도 기반 모델의 학습은 크게 두 단계로 말할 수 있다.
- 지각적 압축(Perceptual Compression) 단계: Autoencoder와 GAN을 이용해 이미지의 시각적 디테일을 압축하는 과정을 의미한다. 이미지의 중요한 정보를 유지하면서 불필요한 세부 사항을 제거한다. 이 단계에서는 고주파 세부 사항을 제거하면서도 의미론적 변화는 거의 학습되지 않는다.
- 의미론적 압축(Semantic Compression) 단계: LDM을 사용하여 이미지의 의미적 내용을 압축한다. 이 과정에서는 이미지의 전반적인 의미와 구성을 이해하고 유지하면서 불필요한 정보를 제거한다. 이 단계에서 실제 생성 모델은 데이터의 의미론적 구성과 개념적 구성을 학습한다.
Latent Diffusion Models (LDMs)의 도입
일반적인 방법을 따르면서도 기존 연구와는 다르게 훈련을 두 가지 구별된 단계로 구성했다.
- 먼저, 지각적으로 데이터 공간과 동등하면서도 차원적으로 더 효율적인 표현 공간을 제공하는 오토인코더(autoencoder)를 훈련한다.
- 그리고 이 학습된 잠재 공간에서 DMs를 훈련한다. 이 접근 방식의 중요한 이점은 오토인코딩 단계를 한 번만 훈련하면 되며, 이를 다양한 DM 훈련에 재사용할 수 있다는 것이다.
이를 통해 다양한 이미지-이미지와 텍스트-이미지 작업에서 효율적으로 디퓨전 모델을 탐구한다. 예를 들어, 교차 주의(cross-attention) 기반 조건부 메커니즘을 사용하여 클래스 조건부, 텍스트-이미지, 레이아웃-이미지 모델을 훈련할 수 있다.
기존 확산 모델의 한계
- DDPM의 구조와 문제점: 기존 확산 모델은 이미지를 점진적으로 노이즈화한 후 반대로 복원하는 과정에서 큰 계산 비용을 필요하다. 특히, 고해상도 이미지를 처리하는 경우, 계산량이 급격히 증가한다.
- 연산 비용의 비효율성: 고해상도 이미지를 직접 생성하려면 매우 큰 모델 파라미터와 계산 자원이 필요하기에 실시간 응용이나 대규모 생성 작업에 어려움이 있다.

기존 모델과 새로 연구한 모델의 성능 비교이다. PSNR과 R-FID는 각각 이미지 품질과 합성된 이미지가 원본과 얼마나 유사한지를 나타내는 지표이다.
- Ours (f=4): 이 방법은 다른 방법들에 비해 더 선명하고 디테일이 잘 보존된 이미지를 생성한다. PSNR이 가장 높고, R-FID는 가장 낮아 원본에 가장 가까운 결과를 보여준다.
- DALL-E (f=8): 이 방법도 꽤 좋은 결과를 보여주지만, Ours 방법보다는 덜 선명하고 R-FID 값이 더 높다.
- VQGAN (f=16): 이 방법은 가장 덜 선명한 결과를 보여주며, PSNR도 가장 낮고 R-FID는 가장 높다. 즉, 원본과의 유사성이 가장 낮다.
잠재 공간에서의 작업
- 잠재 공간의 이점: 잠재 공간에서의 작업은 원본 이미지보다 훨씬 작은 차원에서 이루어지기 때문에 계산 자원을 절약하고 변형이나 생성 작업은 원래 이미지 공간보다 효율적으로 작업할 수 있다.
- 기존의 잠재 공간 활용 방법들: VAE, GAN 등 다양한 모델들이 잠재 공간을 활용한 이미지 생성을 시도해왔으며, 이들 모델의 성과와 한계를 분석한다.
기존 연구와 비교 했을 때 연구의 이점
- 높은 품질의 이미지: 기존 모델들에 비해 더 선명하고 세밀한 이미지를 생성할 수 있다.
- 낮은 계산 비용: 더 적은 자원으로도 고해상도의 이미지를 생성할 수 있다.
- 재사용 가능: Autoencoder는 여러 번 훈련할 필요가 없고, 한 번 훈련한 후 여러 작업에 사용할 수 있다.
- 연구한 모델은 고해상도 합성 작업에서 큰, 일관된 이미지를 렌더링할 수 있으며, 교차 주의 기반의 조건부 메커니즘을 설계하여 다양한 모달리티 학습이 가능합니다.
- 다양한 작업 외에도 DM 훈련을 위해 재사용할 수 있는 사전 훈련된 잠재 디퓨전 및 오토인코딩 모델을 공개했다.
3. Related Work
생성 모델의 문제점

이미지는 매우 고차원적인 데이터이기 때문에, 이를 생성하는 데는 많은 어려움이 있다.
- GANs (생성적 적대 신경망): GANs는 고해상도 이미지를 효율적으로 생성할 수 있지만, 최적화가 어렵고 모든 데이터 분포를 잘 포착하지 못하는 문제가 있다.
- 확률 기반 모델: 이 모델들은 데이터를 잘 모델링하지만, 생성된 이미지의 품질이 GANs만큼 좋지 않다. 특히, 매우 복잡한 계산 구조를 필요로 하며, 고해상도 이미지를 생성하는 데 어려움이 있다.
- Autoregressive Models (ARM): 이 모델들은 데이터 밀도를 잘 추정하지만, 계산이 복잡하고 샘플링 과정이 순차적이어서 고해상도 이미지에는 적합하지 않다.
Diffusion Models (DMs)와 그 한계
최근에는 Diffusion Models (DMs)이 이미지 생성에서 매우 좋은 결과를 보여주고 있다. 이 모델들은 이미지 데이터를 매우 잘 이해하고 모델링할 수 있는 구조를 가지고 있으며, 특히 UNet이라는 구조를 사용하여 뛰어난 성능을 발휘한다. 하지만 DM에도 단점이 존재한다.
- 느린 추론 속도: 이미지를 생성하는 데 시간이 많이 걸립니다.
- 높은 훈련 비용: 고해상도 이미지를 다루려면 많은 계산 자원이 필요합니다.
Latent Diffusion Models (LDMs)의 제안
이러한 문제를 해결하기 위해 아래와 같은 장점이 있는 Latent Diffusion Models (LDMs)을 제안한다.
- 압축된 공간에서의 훈련: LDMs는 원본 이미지 대신 더 낮은 차원의 압축된 공간에서 모델을 훈련시킨다. 이렇게 하면 계산 자원이 절약되고, 훈련과 추론 속도가 빨라진다.
- 고품질 이미지 생성: 압축된 공간에서 훈련해도, 이미지 품질은 거의 저하되지 않는다. 이를 통해 고해상도 이미지를 효율적으로 생성할 수 있다.
두 단계 이미지 합성
이미지 합성의 기존 방법들에서는 각각의 방법이 가지는 단점을 보완하기 위해, 두 단계를 결합하는 방식이 많이 연구되었다.
- VQ-VAE와 VQGAN: 이 모델들은 먼저 이미지의 압축된 표현을 학습하고, 그 후에 이를 기반으로 이미지를 생성한다. 그러나 너무 높은 압축률은 성능을 저하시킬 수 있으며, 적은 압축은 많은 계산 비용을 초래한다.
LDMs는 이러한 문제를 해결하기 위해, 더 효율적으로 고차원의 공간에서 모델을 훈련시키고, 높은 품질의 이미지를 생성할 수 있도록 설계했다. 이를 통해 학습과 생성 모두에서 성능과 효율성을 동시에 달성할 수 있는 것이다.
4. Latent Diffusion Model의 작동 방식

잠재 공간에서의 학습
Pixel Space와 Latent Space:
- 이미지 데이터는 보통 이미지의 각 픽셀이 모두 표현된 고차원 공간인 Pixel Space에서 이루어 진다.
- Latent Space는 Pixel Space의 정보를 압축하여 표현한 저차원 공간이다. LDM에서는 이 Latent Space를 사용하여 이미지 합성을 수행한다. 이렇게 하면 계산 자원을 절약할 수 있다.
LDM의 첫 번째 단계는 고해상도 이미지를 더 낮은 차원의 잠재 공간으로 압축하는 오토인코더(Autoencoder)를 훈련하는 것이다. 이 오토인코더는 이미지의 중요한 정보는 유지하면서, 불필요한 고주파 성분을 제거하여 연산 비용을 줄일 수 있도록 설계되었다. 오토인코더의 인코더는 입력 이미지를 잠재 벡터로 변환하고, 디코더는 이 잠재 벡터로부터 다시 이미지를 복원한다.
이 과정에서 중요한 점은, 이 잠재 공간이 고해상도 이미지의 세부 사항을 잃지 않으면서도 계산 효율성을 높일 수 있도록 최적화된다는 것이다. 이를 통해 LDM은 기존의 픽셀 기반 모델에 비해 훨씬 적은 연산 자원으로 고품질의 이미지를 생성할 수 있게 된다.
확산 모델의 훈련
오토인코더를 통해 생성된 잠재 공간에서, 확산 모델을 훈련합니다. Latent Space에서 Diffusion Process를 통해 이미지를 생성한다. Diffusion Process는 이미지의 노이즈를 점차 줄여가며 원본 이미지로 복원한다. 확산 모델은 기본적으로 노이즈가 있는 잠재 변수에서 원래 이미지를 복원하는 과정을 학습한다. 이 과정은 다단계 마르코프 체인(Markov Chain)으로 모델링되며, 각 단계에서 점진적으로 노이즈를 제거하여 깨끗한 이미지를 생성한다.
이 논문에서는 확산 모델의 훈련을 위해 Denoising time-conditional U-Net이라는 구조가 이 과정에서 중요한 역할을 한다. 이 구조는 이미지를 단계별로 노이즈를 제거하며, 최종적으로 고품질의 이미지를 생성한다. 또한, 이미지의 공간적 구조를 잘 보존하면서도, 고해상도 이미지 생성에 필요한 계산 효율성을 유지할 수 있도록 도와준다. Diffusion Models는 데이터를 학습하기 위해 점차적으로 노이즈를 제거하는 확률적 모델로 LDMs는 이러한 Diffusion Process를 Latent Space에서 수행하며, 저차원 공간에서 작업하기 때문에 계산이 더 효율적이다.
KL 정규화와 VQ 정규화
Latent Space에서 너무 높은 변동성을 피하기 위해, 두 가지 정규화 방법을 이용한다:
- KL-정규화 (KL-reg.): 일반적인 분포에 가까운 Latent Space를 만들기 위해 사용한다.
- VQ-정규화 (VQ-reg.): Vector Quantization 레이어를 사용하여, Latent Space의 변동성을 조정한다.
이 정규화 방법들을 사용하면, 이미지의 중요한 세부 사항을 더 잘 보존할 수 있다.
이 모델은 Latent Space에서 노이즈가 있는 데이터를 입력으로 받아들여, 노이즈를 제거한 결과를 예측하도록 훈련한다. Latent Space에서의 노이즈 제거를 최적화하는 데 중점을 둔다.

- : 노이즈를 나타내는 변로 정규분포 N(0,1)N(0,1)에서 샘플링
- xtx_t: 주어진 시간 tt에서의 노이즈가 섞인 데이터
- ϵθ(xt,t): 주어진 시간 tt에서의 노이즈를 제거한 결과를 예측하는 모델입
- [∥ϵ−ϵθ(xt,t)∥22]: 모델이 예측한 노이즈 제거 결과와 실제 노이즈 간의 차이를 최소화하는 것이 이 모델의 목표
- : Latent Space에서의 노이즈가 섞인 데이터

조건부 이미지 생성
LDM은 단순히 무조건적인 이미지 생성을 넘어, 다양한 조건을 기반으로 LDMs도 조건부 확률 분포 p(z∣y)p를 모델링해서 이미지를 생성할 수 있다. 예를 들어, 텍스트 설명, 레이아웃, 또는 다른 이미지와 같은 입력 조건에 따라 이미지를 생성하는 것이 가능하다. 이를 위해 LDM은 교차 주의 메커니즘(cross-attention mechanism)을 도입하여 다양한 입력 모달리티를 처리할 수 있도록 확장했다.

교차 주의(cross-attention)

- 입력 조건 y를 특정 도메인별 인코더 τθ로 처리하여 중간 표현 τθ(y)를 생성
- 이 중간 표현은 UNet의 중간 레이어에 전달되며, 교차 주의 레이어에서 처리
- 여기서 Q,K,V는 각각 쿼리, 키, 밸류 벡터를 의미하며, 이는 학습 가능한 투영 행렬에 의해 생성
이 방법은 특히 텍스트-이미지 생성에서 강력한 성능을 발휘하며, 특정한 텍스트 설명에 따라 이미지의 내용을 제어할 수 있는 능력을 가진다. 이는 최근에 각광받고 있는 텍스트 기반 이미지 생성 응용 분야에서 매우 유용한 도구가 될 수 있다.
5. Experiment
트레이드오프 분석


LDMs는 서로 다른 다운샘플링 계수(f)를 사용하여 다양한 실험을 진행했다. 여기서 LDM−1은 픽셀 기반 Diffusion Models에 해당하며, f 값이 커질수록 더 강한 압축을 의미한다.
훈련 속도와 품질의 관계
- 다운샘플링 계수가 작은 LDM−1, LDM−2는 훈련 속도가 느리고, f 값이 너무 큰 경우(LDM−32)는 초반에 빠르게 성능이 개선되지만 이후 정체되는 경향을 보였다.
- 적절한 다운샘플링 계수(LDM−4에서 LDM−16)가 효율성과 품질 간의 좋은 균형을 보여주며, 2백만 번의 훈련 후 픽셀 기반 모델(LDM−1)에 비해 현저히 낮은 FID 점수를 기록했다.
샘플링 속도와 FID 점수
- CelebA-HQ와 ImageNet 데이터셋에서 다양한 디노이징 단계에 따른 샘플링 속도와 FID 점수를 비교했다.
- LDM−4와 LDM−8은 픽셀 기반 LDM−1보다 훨씬 낮은 FID 점수를 기록하면서도 샘플 처리 속도에서 상당한 성능 향상을 보여주었다.
Latent Diffusion을 사용한 이미지 생성
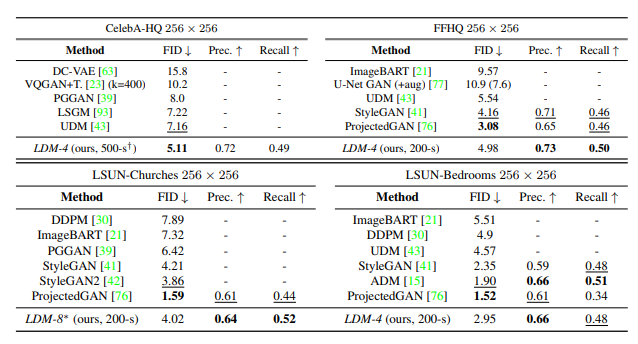
LDMs는 CelebA-HQ, FFHQ, LSUN-Churches, LSUN-Bedrooms와 같은 데이터셋에서 이미지 합성을 수행했다.
샘플 품질 평가
- FID와 Precision-and-Recall 지표를 사용해 평가했다.
- CelebA-HQ에서 FID 5.11을 기록하며 이전의 모든 모델보다 우수한 성능을 보여주었다.
- LSUN-Bedrooms 데이터셋에서는 ADM모델과 비슷한 성능을 보였지만, 파라미터 수와 훈련 자원 측면에서 더 효율적이었다.
GAN 기반 방법들과의 비교
- LDMs는 GAN 기반 방법들에 비해 Precision과 Recall 측면에서 일관되게 우수한 성능을 보였다. 이는 LDMs의 모드 커버링(likelihood-based) 훈련 목표가 적대적 접근 방식보다 더 유리하다는 것을 확인시켜준다.
텍스트-이미지 합성을 위한 트랜스포머 인코더
텍스트-이미지 합성에서는 LDM에 교차 주의(cross-attention) 기반 조건부 방법을 도입하여 이전에는 탐구되지 않았던 다양한 조건부 모달리티를 적용할 수 있게 했다.
텍스트-이미지 모델링

- 이 모델은 LAION-400M 데이터셋을 사용하여 텍스트 프롬프트를 기반으로 이미지를 생성한다.
- 텍스트를 처리하기 위해 BERT 토크나이저를 사용하고, 텍스트 정보를 트랜스포머 구조를 통해 처리한 후, 교차 주의 메커니즘을 통해 UNet에 적용한다.
- 이 모델은 복잡한 사용자 정의 텍스트 프롬프트에도 잘 일반화할 수 있으며, MS-COCO 데이터셋에서 텍스트-이미지 생성 성능을 평가한 결과, 강력한 자율회귀(AR) 및 GAN 기반 방법들을 능가했다.
분류기 없는 디퓨전 가이드
- 샘플 품질을 크게 향상시키기 위해 분류기 없는 디퓨전 가이드를 적용했다. 이는 모델이 텍스트 조건을 더 잘 따르도록 하는 방법이다.
이미지 합성 실험

교차 주의 기반 조건부 메커니즘의 유연성을 분석하기 위해, OpenImages 및 COCO 데이터셋에서 의미적 레이아웃을 기반으로 이미지를 합성하는 모델도 훈련했다.
256² 해상도를 넘어선 합성 샘플링
256² 해상도를 넘어선 합성 샘플링에서는 LDM이 이미지-이미지 변환 모델로 효율적으로 작동할 수 있도록 하는 방법을 연구한다.

일반적인 이미지-이미지 변환
- LDM은 입력 이미지와 공간적으로 정렬된 조건부 정보를 결합하여 의미적 합성, 슈퍼 해상도, 인페인팅(이미지 복원) 등의 작업을 수행할 수 있다.
- 의미적 합성에서는 풍경 이미지와 의미적 지도를 사용하여 모델을 훈련했다. 다운샘플링된 의미적 지도를 Latent Image 표현과 결합하여 256² 해상도의 이미지를 생성할 수 있다.
대형 이미지 생성
- 모델은 256² 해상도로 훈련되었지만, 더 큰 해상도(512²에서 1024²)에서도 일반화할 수 있다.
- 슈퍼 해상도와 인페인팅 작업에서도 이 특성을 활용하여 대형 이미지를 생성할 수 있다.
- 신호 대 잡음비(SNR): Latent Space의 스케일에 의해 유도되는 신호 대 잡음비가 결과에 중요한 영향을 미치며, 이 부분은 Latent Space의 조정에 따라 더 나은 결과를 얻기 위한 실험이 이루어졌다.
슈퍼 해상도(Super-Resolution)와 Latent Diffusion

LDM을 사용하여 슈퍼 해상도 작업을 수행할 때, 저해상도 이미지를 조건부로 사용하여 고해상도 이미지를 생성한다.
- 훈련 과정
- SR3 모델과 유사하게, 이미지 저하(degradation)는 4배 다운샘플링된 비큐빅 인터폴레이션을 사용했다.
- OpenImages에서 사전 훈련된 f=4 오토인코더 모델을 사용하여 저해상도 이미지를 UNet에 입력으로 사용했다.
- 성능 평가
- LDM-SR(Latent Diffusion Model for Super-Resolution)은 FID 점수에서 SR3를 능가했으며, SR3는 IS(Inception Score)에서 더 나은 결과를 보였다.
- PSNR과 SSIM 지표는 이미지의 선명도와 구조를 평가하지만, 인간의 지각과는 다소 차이가 있을 수 있다. PSNR과 SSIM은 더 높은 값을 기록했지만, 이는 종종 고주파수 디테일의 일치보다는 블러 처리를 선호하는 경향이 있다.
- 사용자 연구 결과는 LDM-SR의 성능이 픽셀 기반 베이스라인보다 더 나은 선호도를 보임을 확인했다.
- LDM−BSR (Bicubic Super-Resolution) 모델
- 단일한 비큐빅 저하 과정에 의존하지 않고, 더 다양한 저하 방식을 사용하여 일반화된 슈퍼 해상도 모델을 훈련했다.
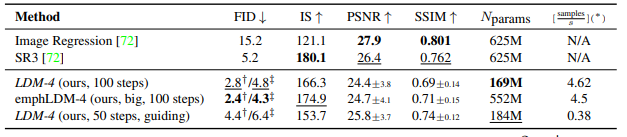
인페인팅(Inpainting)과 Latent Diffusion
인페인팅은 이미지의 손상된 부분을 복원하거나 원치 않는 내용을 대체하는 작업을 의미한다.
- 평가 방법
- LaMa라는 최근 인페인팅 모델과 유사한 프로토콜을 사용하여 평가했으며 이 모델은 Fast Fourier Convolutions를 사용한 특화된 아키텍처를 가지고 있다.
- 설계 선택의 효과 분석
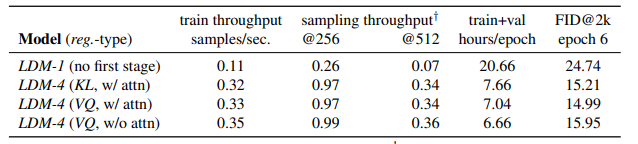
- LDM-1(픽셀 기반)과 LDM-4(잠재 공간 기반) 모델을 비교하여 인페인팅 효율성을 분석했다.
- KL 및 VQ 정규화를 사용한 모델들과 비교하고, 첫 단계에서 주의(attention)를 사용하지 않은 VO-LDM-4 모델도 평가했다.
- 성능 결과
- 픽셀 기반 모델에 비해 잠재 공간 기반 모델이 학습 및 샘플링 속도에서 최소 2.7배 더 빠르고, FID 점수를 최소 1.6배 향상시켰다.
- 다른 인페인팅 접근법과 비교했을 때, 주의 메커니즘을 포함한 LDM 모델이 전체 이미지 품질에서 더 나은 성과를 보였다.
- LaMa 모델은 평균적인 이미지를 복원하는 경향이 있었으나, LDM은 다양한 결과를 생성할 수 있어 사용자 연구에서도 더 높은 선호도를 보였다.
- 확장된 모델
- VQ 정규화된 첫 단계에서 주의 메커니즘 없이 더 큰 모델을 훈련한 결과, 해상도 256²와 512²에서 샘플 품질의 차이를 발견됐다.
- 이를 해결하기 위해 512² 해상도에서 반 에포크 동안 fine-tuning을 하여 새로운 최첨단 FID 점수를 기록했다.

의의 및 한계
이 논문에서 제안된 LDM은 이미지 생성 모델의 새로운 패러다임을 제시하며, 고해상도 이미지 생성을 위한 중요한 진전을 이루었습니다. LDM은 다음과 같은 측면에서 중요한 시사점을 제공하였다
이미지 생성 기술의 효율성 극대화 및 상용화
LDM은 고해상도 이미지 생성의 연산 비용을 크게 줄임으로써, 이 기술의 접근성을 높이고자 한다. 기존의 확산 모델들은 매우 높은 연산 자원을 요구하여, 대규모 연구 기관이나 기업에서만 활용될 수 있는 반면, LDM은 더 적은 자원으로도 유사한 성능을 제공하므로, 더 많은 연구자와 개발자가 이 기술을 활용할 수 있게 된다.
다양한 응용 가능성
LDM은 이미지 생성뿐만 아니라 다양한 응용 분야에서 활용될 수 있는 잠재력을 가지고 있다. 예를 들어, 텍스트-이미지 합성, 이미지 인페인팅, 슈퍼해상도(super-resolution) 등 다양한 이미지 처리 작업에 적용할 수 있으며, 이를 통해 더 창의적이고 유용한 애플리케이션을 개발할 수 있다.
지속 가능한 인공지능
LDM은 고해상도 이미지 생성의 연산 비용을 줄임으로써, 인공지능 모델 훈련에서 발생하는 에너지 소비와 탄소 배출을 줄이는 데 기여할 수 있다. 이는 인공지능 연구의 지속 가능성을 높이는 데 중요한 역할을 할 수 있다.
속도 문제
LDMs는 픽셀 기반 접근법에 비해 계산 요구 사항을 크게 줄였지만, 여전히 GANs보다 샘플링 속도가 느리다는 문제점이 있다.
정밀도 문제
높은 정밀도가 요구되는 작업에서는 LDMs의 사용이 문제가 될 수 있다. 특히, f = 4 오토인코딩 모델에서는 이미지 품질 손실이 매우 작지만, 픽셀 수준에서 정밀한 정확도가 필요한 작업에서는 재구성 능력이 한계가 될 수 있다. 이와 관련하여 논문에서는 초해상도 모델(Sec. 4.4)의 성능이 이미 어느 정도 제한되어 있다고 언급한다.
사회적 영향 (Societal Impact)
- 긍정적인 영향: 생성 모델은 이미지와 같은 미디어에 대한 다양한 창의적 응용을 가능하게 하며, 특히 LDMs처럼 훈련과 추론 비용을 줄이는 접근법은 기술에 대한 접근성을 높이고 탐구를 민주화할 수 있는 잠재력이 있다.
- 부정적인 영향: 그러나 이러한 기술은 조작된 데이터를 만들고 확산시키는 것을 더 쉽게 만들 수 있어, 허위 정보나 스팸의 확산을 초래할 수 있다. 특히, 고의적으로 이미지를 조작하는 "딥페이크" 문제는 여성들이 불균형적으로 피해를 입는 경우가 많다.
- 데이터 프라이버시 문제: 생성 모델은 훈련 데이터의 일부를 노출할 수 있으며, 민감하거나 개인적인 정보가 포함된 데이터가 명시적 동의 없이 수집된 경우, 이는 큰 문제가 될 수 있다. 이미지의 확산 모델이 이러한 문제에 얼마나 취약한지는 아직 완전히 이해되지 않았다.
- 편향 문제: 딥러닝 모듈은 데이터에 이미 존재하는 편향을 재생산하거나 악화시킬 수 있다. 확산 모델은 GAN 기반 접근법보다 데이터 분포를 더 잘 포괄하지만, 논문에서 제시된 적대적 훈련과 가능도 기반 목표를 결합한 두 단계 접근법이 데이터를 어떻게 잘못 표현할 수 있는지는 여전히 중요한 연구 과제이다.
여기까지가 논문 리뷰이다. 예전에 트위터(현 X)에서 테일러 스위프트에 대한 무자비한 딥페이크 확산으로 한 때 논란이 발생했던 적이 있었는데 현재 트위터를 인수한 일론 머스크가 새로운 AI Grok을 선보이면서 어떠한 윤리적인 조건 제한 없는 이미지 생성이 가능케 해서 문제가 되고 있다.
보너스로 아래는 이미지 생성 AI로 생성해본 "새로운 불속성의 전설의 포켓몬 이미지를 만들어줘"라고 해서 만들어진 이미지이다. 유명한 미드 저니나 Novel AI는 결제 이슈로 없다.
DALL-E 생성


아주 멋있는 펄기아, 디아루가 느낌의 불속성 포켓몬이 나왔다.
CANVA 생성




약간 귀여운 느낌의 친구들이 나왔다
Microsoft Designer 생성


얘는 포켓몬을 모르나...........
자동으로 프롬프트를 개선 해주는 기능이 있길래 a new fire attribute legendary Pokemon를 입력하고 A majestic legendary Pokemon with a fiery red coat and a fierce expression stands tall and proud, ready to unleash its powerful flames on any challenger.로 개선해서 생성해봤다.



오 가장 포켓몬 같은 일러스트가 나왔다
Adobe Firefly 생성


얘도 포켓몬 뭔지 모르는 건지...그래서 자동생성된 프롬프트를 넣어봤는데...


다시 Microsoft에서 프롬프트를 자동 생성해서 A majestic, fiery legendary Pokemon stands tall in a dark, rocky landscape. Its body is covered in shimmering red scales, and its eyes glow with an intense heat. Its wings are spread wide, and its sharp claws are poised for battle. The Pokemon's long, flowing tail flickers with flames, and its roar echoes across the mountains. This is the ultimate fire Pokemon, a true master of the element.를 넣어봤는데


진짜 포켓몬 모르는 것 같다
'일상 > 컴퓨터' 카테고리의 다른 글
| Fake News Detection 모델 파이썬으로 구현해보기 (7) | 2024.09.01 |
|---|---|
| [Tableau 태블로] 사용 편의를 높이는 그래프 확대 & 도구 설명 (0) | 2024.08.25 |
| [논문 리뷰] 트랜스포머 transformer 기반 가짜 뉴스 탐지 (4) | 2024.08.11 |
| Open AI & Stremalit으로 캐릭터 챗봇 만들기 (5) | 2024.08.04 |
| [GitHub 깃 & 깃허브 입문] 웹에서 Git 배우기 (0) | 2023.05.20 |