https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
딥러닝의 발전과 함께 심층 신경망의 훈련이 점점 어려워졌고, 이는 주로 기울기 소실 문제 때문이다. 이를 해결하기 위해 ResNet이 등장했다. ResNet은 '잔차 학습'이라는 개념을 도입하여 심층 네트워크에서도 효과적으로 학습할 수 있도록 설계되었다. 딥러닝 분야에서 ResNet은 정말 혁신적인 모델로 자리 잡았다. 이 모델은 깊은 신경망을 효과적으로 학습할 수 있도록 도와주는 Residual Learning Framework를 기반으로 하고 있다. 이번 포스트에서는 ResNet 논문을 자세히 분석하고, 그 구조와 성능, 그리고 코드 구현 방법에 대해 알아보겠다.
ResNet 논문
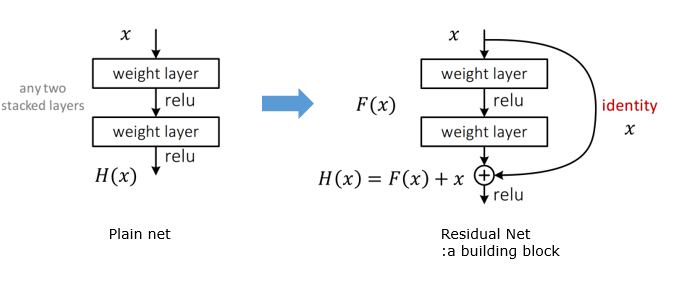
Resnet, Deep residual Learning Framework
Abstract
깊은 신경망은 학습하기가 어렵다는 문제가 있다. ResNet(Residual Network)은 이러한 문제를 해결하기 위해 잔차 학습(residual learning) 프레임워크를 제안했다. 기존의 레이어에서 학습해야 하는 함수를 그대로 학습하는 대신, 입력을 기준으로 한 잔차 함수를 학습하는 방식으로 레이어를 재구성했다. 이 방식을 통해 훨씬 더 깊은 네트워크를 최적화하는 것이 용이해졌으며, 네트워크의 깊이가 증가함에 따라 정확도도 향상된다는 것을 실험적으로 입증했다.
ImageNet 데이터셋에서 최대 152개의 레이어로 구성된 Residual 네트워크를 평가한 결과, 기존의 VGG 네트워크보다 8배 깊으면서도 복잡도는 낮은 모델을 만들 수 있었다. 이 모델을 앙상블로 사용한 결과, ImageNet 테스트 세트에서 3.57%의 오류율을 기록하며 ILSVRC 2015 분류 대회에서 1위를 차지했다. 또한, CIFAR-10 데이터셋에서 100층 및 1000층의 네트워크에 대한 분석도 제시했다.
깊은 표현은 여러 시각 인식 작업에서 중요한 역할을 한다. ResNet은 COCO 객체 검출 데이터셋에서도 28%의 상대적 성능 향상을 보여주었으며, ImageNet 검출, ImageNet 위치 지정, COCO 검출, COCO 세그멘테이션과 같은 ILSVRC 및 COCO 2015 대회에서 1위를 차지하는 기반이 되었다.

Introduction
ResNet은 딥러닝 모델을 더 깊게 쌓으면서 발생하는 문제를 해결하기 위해 도입된 새로운 학습 방법이다. 딥 컨볼루션 신경망(Deep Convolutional Neural Networks)은 이미지 분류 작업에서 큰 발전을 이루어냈고, 네트워크의 깊이를 늘리면 더욱 풍부한 특징을 학습할 수 있게 된다. 특히 ImageNet과 같은 복잡한 데이터셋에서 매우 깊은 네트워크가 좋은 성능을 보이며, 이러한 깊이는 시각 인식 문제 해결에 중요한 역할을 한다.
그러나 더 많은 레이어를 쌓는다고 해서 무조건 더 좋은 성능을 내는 것은 아니다. 깊어질수록 발생하는 대표적인 문제가 바로 '기울기 소실(vanishing gradients)'이나 '기울기 폭발(exploding gradients)' 현상이다. 이 문제는 주로 초기화 기법과 정규화 레이어 등을 통해 어느 정도 해결되었지만, 네트워크가 깊어질수록 학습 정확도가 떨어지는 '성능 저하(degradation)' 문제가 여전히 남아 있었다.
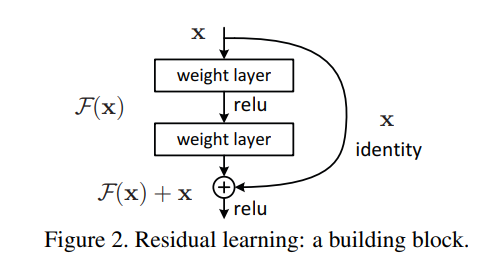
ResNet은 이러한 성능 저하 문제를 해결하기 위해 '잔차 학습(residual learning)'이라는 새로운 개념을 도입했다. 일반적으로 신경망의 각 레이어는 원하는 출력을 직접 학습하게 되지만, 잔차 학습은 이를 '잔차 함수(residual function)'로 변환해 학습한다. 즉, 레이어들이 목표한 함수를 직접 학습하는 대신, 잔차 함수 F(x) = H(x) - x를 학습하게 되고, 이를 다시 원래의 함수로 복원하는 방식(F(x) + x)을 사용한다. 이 방식은 원래의 함수를 직접 학습하는 것보다 최적화가 더 쉽다는 가정을 바탕으로 한다.
잔차 학습의 핵심은 '쇼트컷 연결(shortcut connection)'이다. 이는 일부 레이어를 건너뛰면서 입력 값을 그대로 다음 레이어로 전달하는 방법이다. 이러한 연결은 추가적인 파라미터나 계산 복잡도를 증가시키지 않으며, 기존의 신경망 학습 방식인 확률적 경사 하강법(SGD)으로 학습이 가능하다.
ResNet은 ImageNet과 CIFAR-10 데이터셋에서 실험을 통해 기존 모델보다 더 깊은 네트워크를 성공적으로 학습할 수 있음을 보여줬다. 특히, ImageNet에서는 152층의 ResNet이 VGG 네트워크보다 훨씬 깊으면서도 계산 복잡도는 낮고, ILSVRC 2015 이미지 분류 대회에서 1위를 차지했다. 또한, COCO와 같은 다른 시각 인식 작업에서도 1위를 차지하면서 잔차 학습이 다양한 문제에 효과적으로 적용될 수 있음을 증명했다.
잔차 학습은 비전(vision) 분야뿐만 아니라 다른 영역에서도 활용될 수 있는 매우 일반적인 원칙으로, 더 복잡한 문제에서도 효과적인 솔루션을 제공할 수 있다. ResNet은 신경망의 깊이를 늘리는 과정에서 발생하는 문제를 해결하고, 더 나은 성능을 제공하는 새로운 학습 방법으로 자리잡았다.
Related Work
ResNet 논문에서 다루는 주요 개념은 잔차 학습(residual learning)과 쇼트컷 연결(shortcut connections)이다. 이 두 개념은 기존 연구에서 이미 중요한 역할을 해왔으며, ResNet의 성공적인 학습에 중요한 기초가 된다.
잔차 표현 (Residual Representations)
이미지 인식 분야에서는 VLAD와 Fisher Vector라는 방법이 잔차 벡터를 이용해 이미지를 표현하는 강력한 방식으로 사용되었다. 예를 들어, VLAD는 이미지 검색과 분류에서 효과적인 성능을 보이며, Fisher Vector는 이 방법의 확률적 버전이다. 이런 방식은 이미지나 저차원 비전 작업에서도 최적화 과정을 단순하게 만들어주는 역할을 한다.
또한, Multigrid 방법과 계층적 기저 사전조건화 같은 기술도 잔차 솔루션을 이용해 문제를 여러 스케일에서 나누어 해결하는데, 이 방법들이 기존의 방법들보다 훨씬 빠르게 수렴하는 것으로 나타났다. 즉, 이런 잔차 기반 접근은 다양한 문제에서 최적화 과정을 더 쉽게 만든다.
쇼트컷 연결 (Shortcut Connections)
신경망 학습에서 쇼트컷 연결은 오랜 시간 동안 연구되어 왔다. 과거에는 다층 퍼셉트론(MLP) 훈련 시 네트워크 입력과 출력을 직접 연결하는 선형 레이어를 추가하는 방식이 있었다. 또한, 기울기 소실 문제를 해결하기 위해 일부 연구에서는 중간 레이어를 보조 분류기와 연결하는 방식을 도입했다.

ResNet과 비슷한 시기에 발표된 하이웨이 네트워크(highway networks)는 데이터에 따라 열리거나 닫히는 게이트 기능이 있는 쇼트컷 연결을 도입했다. 그러나 ResNet의 차이점은 아이덴티티 쇼트컷을 사용한다는 점이다. 즉, ResNet에서는 정보를 항상 그대로 통과시키면서 추가로 학습해야 할 잔차 함수만 학습한다. 이 방식은 더 깊은 네트워크에서도 효율적으로 작동하며, 100층이 넘는 매우 깊은 신경망에서도 뛰어난 성능을 낼 수 있게 해준다.
따라서, ResNet의 잔차 학습과 아이덴티티 쇼트컷 연결은 기존의 깊은 네트워크가 가진 문제점을 극복하고, 더 깊은 네트워크에서도 학습이 잘 이루어지도록 돕는 핵심 기술이다.
3. Deep Residual Learning
ResNet의 핵심 개념 중 하나는 잔차 학습(Residual Learning)이다. 이 방법은 더 깊은 신경망을 효율적으로 학습할 수 있도록 돕는 중요한 기술로, 이를 통해 깊은 네트워크에서도 성능 저하 없이 안정적인 학습이 가능해진다.
3.1 Residual Learning
잔차 학습은, 기존 신경망이 입력과 출력 사이의 복잡한 함수를 학습하려고 하는 대신, 그 함수와 입력 값의 차이, 즉 잔차 함수를 학습하도록 하는 방법이다. 쉽게 말해, 신경망이 H(x)라는 목표 함수를 직접 학습하는 것이 아니라, F(x) = H(x) - x라는 차이값을 학습하게 만든다. 그러면 원래의 함수는 F(x) + x가 된다.
이렇게 하면 복잡한 함수 대신 잔차, 즉 더 작은 변화를 학습하는 것이므로 학습이 훨씬 수월해진다. 만약 최적의 해결책이 입력과 출력이 같은 아이덴티티 맵핑이라면, 신경망은 복잡한 함수를 학습하는 대신 잔차를 0으로 만드는 작업만 하면 된다. 이로 인해 학습 과정이 더욱 간단해진다.
잔차 학습은 특히 깊은 신경망에서 성능이 떨어지는 문제를 해결하는 데 도움을 준다. 깊은 네트워크는 층이 쌓일수록 학습이 어려워지거나 성능이 나빠지는데, 잔차 학습을 통해 이러한 문제를 극복할 수 있다.
3.2 Shortcut Connections
잔차 학습을 실제로 구현하기 위해 ResNet은 쇼트컷 연결을 사용한다. 쇼트컷 연결은 쉽게 말해, 신경망의 몇 개 층을 뛰어넘어 입력 값을 그대로 다음 층으로 전달하는 방식이다. 이때, 입력값을 중간 출력에 더해주는 방식으로 계산한다.
예를 들어, 두 개의 층으로 이루어진 블록에서 F(x)는 두 개의 가중치 행렬로 계산된 함수이고, 최종 출력은 F(x) + x로 계산된다. 이처럼 입력과 출력을 원소별 덧셈으로 합산하는 방식으로 쇼트컷 연결을 구현한다.
이 방법의 큰 장점은 추가적인 파라미터나 계산 비용이 들지 않는다는 것이다. 즉, 잔차 네트워크와 기존 네트워크를 비교할 때 파라미터 수나 계산 복잡도를 동일하게 유지하면서 성능을 비교할 수 있다.
만약 입력과 출력의 차원이 맞지 않는 경우, Ws라는 선형 변환을 통해 차원을 맞출 수 있다. 그러나 실험 결과, 대부분의 경우 아이덴티티 맵핑만으로도 충분히 성능이 잘 나오기 때문에 차원이 다를 때만 Ws를 사용하는 것이 효율적이다.
이 방법은 컨볼루션 레이어에도 동일하게 적용할 수 있다. 컨볼루션 레이어에서도 잔차 학습을 적용해 입력과 출력을 피처 맵에서 더하는 방식으로 사용한다.
3.3 Network Architectures
ResNet 논문에서는 Plain Networks와 Residual Networks를 실험했으며, 여기서는 ImageNet 데이터셋에 대한 두 가지 모델을 설명한다.
Plain Network
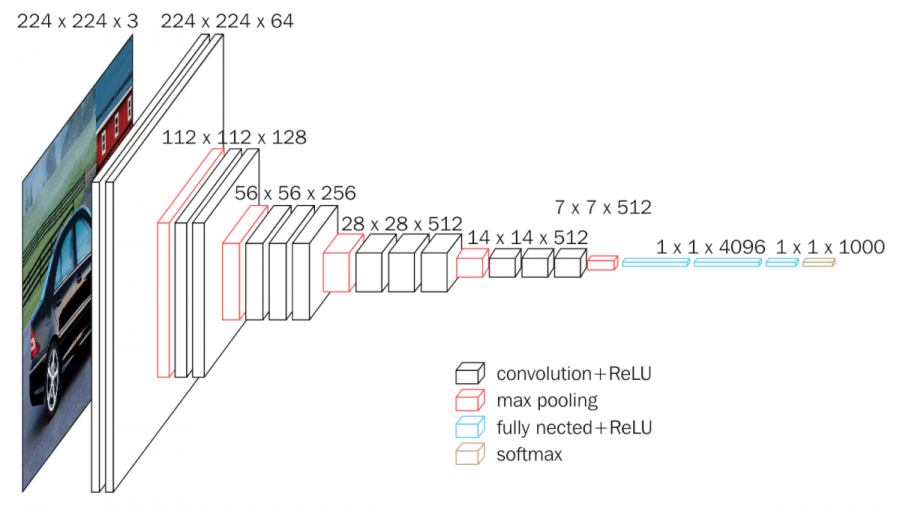
Plain Network는 VGG Networks에서 영감을 받아 설계되었다. 이 네트워크는 주로 3×3 필터를 사용하는 Convolutional Layers로 구성되어 있으며, 두 가지 설계 규칙을 따른다:
- 출력 Feature Map 크기가 같으면 해당 레이어의 필터 개수도 동일하게 설정한다.
- 출력 Feature Map 크기가 절반으로 줄어들 때, 필터 개수를 두 배로 늘려 각 레이어의 시간 복잡도를 유지한다.
다운샘플링은 Stride 2를 사용하는 Convolutional Layer로 수행하며, 네트워크의 마지막에는 Global Average Pooling Layer와 1000개의 클래스 분류를 위한 Fully Connected Layer (Softmax)가 있다. 총 34개의 Weighted Layers로 구성되어 있다.
이 모델은 VGG Networks보다 적은 필터 수와 낮은 복잡도를 가지고 있다. 예를 들어, 34-layer 네트워크는 3.6 billion FLOPs로, VGG-19의 18%에 해당하는 복잡도만 사용한다.
Residual Network
Residual Network는 앞서 설명한 Plain Network에 Shortcut Connections을 추가한 것이다. 이 연결은 네트워크를 Residual Version으로 바꾸며, Identity Mapping을 수행하는 쇼트컷을 통해 입력과 출력의 차원을 맞춘다.
Identity Shortcuts는 입력과 출력의 차원이 같을 때 사용된다. 하지만 차원이 다른 경우, 두 가지 방법을 사용한다:
- Option A: Identity Mapping을 유지하면서 차원이 늘어날 때 Zero Padding을 사용한다.
- Option B: 1×1 Convolutions을 사용해 차원을 맞추는 Projection Shortcut을 사용한다.
이러한 Shortcuts는 Feature Map의 크기가 절반으로 줄어들 때 Stride 2로 수행된다.

3.4 Implementation
ResNet의 ImageNet 구현은 Scale Augmentation을 포함한 여러 표준적인 데이터 증강 방식을 따른다. 이미지의 짧은 변은 256에서 480 사이로 랜덤하게 리사이즈되며, 224×224 크기의 Crop이 이미지 또는 Horizontal Flip에서 랜덤하게 샘플링된다. Batch Normalization (BN)은 각 Convolution 이후 적용되며, 가중치 초기화는 기존 방식을 따른다.
학습은 SGD를 사용하며 미니배치 크기는 256이다. 학습률은 0.1에서 시작하고, 60만 번의 반복 동안 학습이 진행되며, 오류가 정체되면 학습률은 10배 감소한다. Weight Decay는 0.0001, Momentum은 0.9로 설정된다.
테스트 시에는 10-crop 방식을 사용해 성능을 비교하며, 여러 Multi-scale에서 평균을 내어 최종 결과를 도출한다.
이후 Experiment 내용
4.1 ImageNet Classification
ImageNet 2012 데이터셋을 사용하여 ResNet을 평가했다. 이 데이터셋은 1000개의 클래스, 128만 개의 학습 이미지, 5만 개의 검증 이미지, 10만 개의 테스트 이미지로 구성되어 있으며, 모델의 성능은 Top-1과 Top-5 오류율로 측정되었다.
Plain Networks
먼저 18-layer와 34-layer Plain Networks를 평가했다. 34-layer 네트워크는 18-layer보다 더 깊지만, 실험 결과 34-layer 네트워크의 검증 오류가 18-layer 네트워크보다 더 높았다. 이는 degradation problem을 나타내는 것으로, 네트워크가 깊어지면 학습 오류가 증가하는 현상이다. 이 문제는, 깊은 네트워크가 더 큰 솔루션 공간을 가짐에도 불구하고, 최적화가 어렵다는 것을 시사한다.
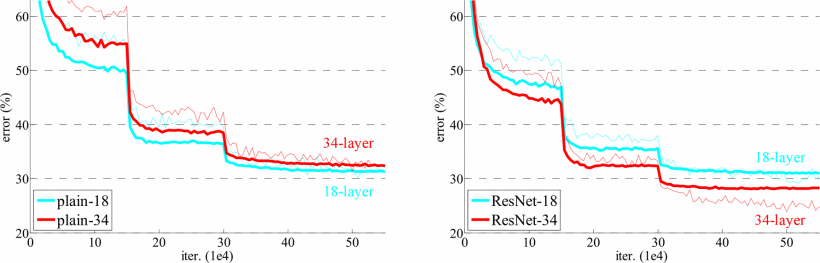
Residual Networks
다음으로 Residual Networks (ResNets)를 평가했다. ResNet에서는 각 3×3 필터 쌍에 shortcut connections을 추가해 네트워크가 더 깊어질수록 성능이 향상되도록 설계했다. 실험 결과, 34-layer ResNet이 18-layer ResNet보다 성능이 2.8% 더 좋았으며, degradation problem도 해결되었다. 또한, Plain Networks와 비교했을 때 34-layer ResNet은 top-1 오류를 3.5% 줄였다.
Identity vs. Projection Shortcuts
Identity shortcuts는 파라미터가 추가되지 않아 네트워크 복잡도를 높이지 않으면서도 학습을 빠르게 할 수 있었다. Projection shortcuts는 차원 증가 시 사용되며, 실험 결과 Projection shortcuts이 더 나은 성능을 보였지만, 성능 차이는 크지 않아 복잡도를 줄이기 위해 Identity shortcuts가 기본적으로 사용되었다.

Deeper Bottleneck Architectures
더 깊은 네트워크를 설계하기 위해 bottleneck 구조를 도입했다. Bottleneck 구조는 3개의 층(1×1, 3×3, 1×1 컨볼루션)을 쌓아 깊이를 늘리면서도 계산 복잡도는 유지했다. 이를 통해 50, 101, 152-layer ResNet을 구성했고, 152-layer ResNet은 11.3 billion FLOPs로 VGG-16/19보다 낮은 복잡도를 가졌다.
50/101/152-Layer ResNets
50, 101, 152-layer ResNets는 깊이가 늘어남에 따라 성능이 크게 향상되었으며, 34-layer ResNet보다 훨씬 더 높은 정확도를 보여주었다. 특히 152-layer ResNet은 VGG 네트워크보다 복잡도는 낮으면서도 훨씬 더 나은 성능을 기록했다.
Comparisons with State-of-the-Art Methods
ResNet은 기존의 최첨단 모델과 비교하여 훨씬 뛰어난 성능을 보였다. 특히 152-layer ResNet의 top-5 검증 오류율은 4.49%로, 이전의 앙상블 모델을 뛰어넘었다. 앙상블 기법을 사용하여 3.57% top-5 오류를 기록하며, ILSVRC 2015에서 1위를 차지했다.
4.2 CIFAR-10 and Analysis
ResNet은 CIFAR-10 데이터셋에서도 평가되었다. 이 데이터셋은 10개의 클래스로 이루어진 50,000개의 학습 이미지와 10,000개의 테스트 이미지를 포함한다. 이번 실험은 간단한 아키텍처를 사용해 extremely deep networks의 동작을 분석하는 데 중점을 두었다.
Network Architecture
네트워크 구조는 ImageNet에서 사용된 것과 유사하다. 네트워크의 입력은 32×32 크기의 이미지이며, 각 픽셀의 평균을 빼서 전처리한 후 3×3 컨볼루션을 사용한다. 6n개의 레이어를 사용해 feature map 크기가 32, 16, 8로 줄어들며, 각 크기마다 2n개의 레이어가 적용된다. 필터의 개수는 16, 32, 64로 점진적으로 증가하며, 다운샘플링은 스트라이드가 2인 컨볼루션을 통해 수행된다. 네트워크는 global average pooling과 10-way fully connected layer, 그리고 softmax로 끝난다. 총 6n+2개의 가중치 레이어가 쌓인다.
Plain Networks vs. ResNets
Plain networks와 ResNets를 각각 비교했다. Plain networks에서는 깊이가 깊어질수록 학습 오류가 증가하는 현상이 나타났는데, 이는 ImageNet에서도 동일하게 관찰된 현상으로, 이러한 최적화 문제는 근본적인 문제로 보인다. 반면, ResNets는 이러한 최적화 문제를 해결하고 깊이가 깊어질수록 정확도가 높아지는 것을 확인했다.

ResNet-110
더 나아가, 110-layer ResNet을 실험했는데, 초기 학습률 0.1은 학습이 시작되기에 너무 컸고, 이를 해결하기 위해 0.01로 학습을 "워밍업"한 후 0.1로 돌아와 학습을 이어갔다. 이 110-layer ResNet은 좋은 수렴을 보였고, 다른 얇고 깊은 네트워크인 FitNet이나 Highway보다 파라미터는 적으면서도 state-of-the-art 결과(6.43%)를 기록했다.
Exploring over 1000 Layers
ResNet의 깊이를 1000 레이어 이상으로 확장하는 실험도 진행했다. 1202-layer 네트워크는 최적화 문제 없이 0.1% 미만의 학습 오류를 달성했지만, 테스트 오류는 110-layer 네트워크보다 높았다. 이는 overfitting으로 인한 문제로 보이며, 이러한 작은 데이터셋에 비해 1202-layer 네트워크가 지나치게 크기 때문일 수 있다.
Layer Responses Analysis

Fig. 7에서는 레이어의 출력 표준 편차를 분석한 결과, ResNets는 일반적으로 Plain networks보다 더 작은 응답을 보여주었다. 이는 residual functions이 비잔차 함수에 비해 더 작은 변화를 일으킨다는 것을 시사한다.
4.3 Object Detection on Pascal and MS COCO
ResNet은 PASCAL VOC 2007/2012와 MS COCO 데이터셋에서 객체 탐지 작업에서도 좋은 성능을 보였다. 이 실험에서는 Faster R-CNN을 탐지 방법으로 사용했으며, VGG-16을 ResNet-101로 교체했을 때 성능 향상을 측정했다. 탐지 모델의 구현은 두 네트워크 모두 동일하게 유지되어, 성능 차이는 네트워크 자체의 개선으로 인한 것이다.
특히, COCO 데이터셋에서 ResNet-101을 사용하면 COCO의 표준 지표인 mAP@에서 6.0%의 성능 향상을 얻었고, 이는 28%의 상대적 개선이다. 이는 ResNet이 학습한 표현 덕분에 얻어진 성과다.
ResNet을 기반으로 한 깊은 네트워크는 ILSVRC와 COCO 2015 대회의 여러 트랙에서도 1위를 차지했다. 여기에는 ImageNet detection, ImageNet localization, COCO detection, COCO segmentation이 포함된다.
간단하게 중요한 포인트만 다시 짚고 가자면, 기존의 신경망에서는 층이 깊어질수록 학습이 어려워지는 문제가 있었는데, ResNet은 이를 해결하기 위해 skip connection을 도입했다. 이로 인해 네트워크가 더 깊어져도 성능이 저하되지 않고 오히려 향상되는 결과를 가져왔다.
TensorFlow에서는 다양한 모델과 과제에 대해 튜토리얼과 가이드를 제공한다. 이번에는 ResNet 관련 튜토리얼을 해보자. 논문과 유사하게 CIFAR 데이터 세트를 사용하고 있다.
https://www.tensorflow.org/tfmodels/vision/image_classification
Image classification with Model Garden | TensorFlow Core
Image classification with Model Garden Stay organized with collections Save and categorize content based on your preferences. This tutorial fine-tunes a Residual Network (ResNet) from the TensorFlow Model Garden package (tensorflow-models) to classify imag
www.tensorflow.org
가이드에서는 TensorFlow Model Garden 패키지의 Residual Network(ResNet)를 미세 조정하여 사용한다. Model Garden에는 TensorFlow의 고급 API로 구현된 최첨단 비전 모델 컬렉션이 포함되어 있다.
먼저 필요한 모듈을 설치하고 라이브러리를 가져온다.
!pip install -U -q "tf-models-official"
import pprint
import tempfile
from IPython import display
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds사전에 학습된 ResNet-18 모델을 불러오기 위해 패키지 tensorflow_models을 불러와준다.
import tensorflow_models as tfm
# These are not in the tfm public API for v2.9. They will be available in v2.10
from official.vision.serving import export_saved_model_lib
import official.core.train_libCIFAR10 데이터 세트에는 상호 배타적인 10개 클래스에 속하는 60,000개의 컬러 이미지가 포함되어 있으며, 각 클래스에는 6,000개의 이미지가 존재한다. Model Garden에서 모델을 정의하는 매개변수 컬렉션을 config 라고 하며, Model Garden은 factory를 통해 알려진 매개변수 집합을 기반으로 config를 생성할 수 있다. resnet imagenet에 특화되어 사전 정의된 매개변수를 사용한다.
exp_config = tfm.core.exp_factory.get_exp_config('resnet_imagenet')
tfds_name = 'cifar10'
ds,ds_info = tfds.load(
tfds_name,
with_info=True)
ds_info이후 CIFAR10에 알맞게 조정을 해준다.
# Configure model
exp_config.task.model.num_classes = 10
exp_config.task.model.input_size = list(ds_info.features["image"].shape)
exp_config.task.model.backbone.resnet.model_id = 18
# Configure training and testing data
batch_size = 128
exp_config.task.train_data.input_path = ''
exp_config.task.train_data.tfds_name = tfds_name
exp_config.task.train_data.tfds_split = 'train'
exp_config.task.train_data.global_batch_size = batch_size
exp_config.task.validation_data.input_path = ''
exp_config.task.validation_data.tfds_name = tfds_name
exp_config.task.validation_data.tfds_split = 'test'
exp_config.task.validation_data.global_batch_size = batch_size
logical_device_names = [logical_device.name for logical_device in tf.config.list_logical_devices()]
if 'GPU' in ''.join(logical_device_names):
print('This may be broken in Colab.')
device = 'GPU'
elif 'TPU' in ''.join(logical_device_names):
print('This may be broken in Colab.')
device = 'TPU'
else:
print('Running on CPU is slow, so only train for a few steps.')
device = 'CPU'
if device=='CPU':
train_steps = 20
exp_config.trainer.steps_per_loop = 5
else:
train_steps=5000
exp_config.trainer.steps_per_loop = 100
exp_config.trainer.summary_interval = 100
exp_config.trainer.checkpoint_interval = train_steps
exp_config.trainer.validation_interval = 1000
exp_config.trainer.validation_steps = ds_info.splits['test'].num_examples // batch_size
exp_config.trainer.train_steps = train_steps
exp_config.trainer.optimizer_config.learning_rate.type = 'cosine'
exp_config.trainer.optimizer_config.learning_rate.cosine.decay_steps = train_steps
exp_config.trainer.optimizer_config.learning_rate.cosine.initial_learning_rate = 0.1
exp_config.trainer.optimizer_config.warmup.linear.warmup_steps = 100이후 데이터를 시각화해야하는데, TensorFlow에서 제공한 코드대로 실행을 해도 코랩에서는 시각화가 되지 않을 수 있다. 그럴 때는 아래 코드를 먼저 추가 실행한 후 시각화 코드를 실행해준다.
%matplotlib inlinedef show_batch(images, labels, predictions=None):
plt.figure(figsize=(10, 10))
min = images.numpy().min()
max = images.numpy().max()
delta = max - min
for i in range(12):
plt.subplot(6, 6, i + 1)
plt.imshow((images[i]-min) / delta)
if predictions is None:
plt.title(label_info.int2str(labels[i]))
else:
color = 'g' if labels[i] == predictions[i] else 'r'
plt.title(label_info.int2str(predictions[i]), color=color)
plt.axis("off")
plt.show()추가적으로 아래 코드는 코랩에서 이미지가 출력이 안돼서 이것저것 실험해보다가 위의 솔루션을 찾았는데, 만약 위의 코드를 적용하지 않고 모두 실행했다가 시각화만 다시 하면 이전에 안되었던 시각화가 한번에 나오니 너무 놀라지 말자.
TensorFlow 가이드대로 훈련 데이터 시각화까지 실행하면 아래와 같은 시각화들이 나온다.

첫번째로는 히스토그램이 출력된다. 입력된 이미지 데이터의 값 분포를 나타내는 히스토그램으로, 값이 표준 정규 분포 형태로 나타나며 이는 이미지 데이터가 전처리 과정에서 평균과 표준 편차를 사용하여 정규화되었음을 알 수 있다.

히스토그램 이후 2개의 시각화 데이터셋의 훈련 데이터 시각화이다. CIFAR-10 데이터셋의 훈련 샘플이 시각화되어 있고, truck, ship, automobile, frog, horse 등 클래스별로 이미지가 출력된 것이다.

테스트 데이터에 대해서는 이렇게 출력이 된다.
이제 위에서 구성한 모델에 대하여 데이터로 훈련하고 평가지표를 출력해보자.
model, eval_logs = tfm.core.train_lib.run_experiment(
distribution_strategy=distribution_strategy,
task=task,
mode='train_and_eval',
params=exp_config,
model_dir=model_dir,
run_post_eval=True)평가지표는 아래 코드로 출력이 가능하다.
for key, value in eval_logs.items():
if isinstance(value, tf.Tensor):
value = value.numpy()
print(f'{key:20}: {value:.3f}')accuracy : 0.113
top_5_accuracy : 0.478
validation_loss : 2.609
steps_per_second : 3.789
성능은 위와 같이 나왔다.
이후 훈련 이후 모델 예측 결과를 시각화하면 아래와 같이 출력된다.


예측 결과에서 문구는 CPU에서 학습했을 때 출력되게 설정되어 있다. CPU에서 모델을 실행할 때, 학습 속도가 느려서 많은 학습 단계를 거치기 어렵기 때문에 이러한 문구가 표시되며, 이는 모델이 아직 초기 학습 단계에 있다는 점을 알려주는 것이다.
"The model was only trained for a few steps, it is not expected to do well."는 모델이 아주 적은 학습 스텝(epochs 또는 iterations)만 거쳤기 때문에, 성능이 좋지 않을 것이라는 의미이다. 모델이 아직 충분한 데이터에 노출되지 않았고, 가중치가 최적화되지 않았기 때문에 예측 정확도가 낮을 가능성이 크다.
"The model was only trained for a few steps, it is not expected to do better than random."는 모델이 랜덤하게 예측하는 것과 크게 다르지 않을 가능성이 크다는 문구다. 즉, 현재 학습된 모델은 마치 무작위로 추측하는 것과 같은 성능을 보여줄 수 있다는 경고이다.
ResNet을 이용한 실습에는 이렇게 이미지 분류 실습이 많다. ResNet에 적용된 Residual Block 개념은 딥러닝 모델이 더욱 깊어질 수 있는 가능성을 열어주었으며 실제로 많은 연구자들이 이를 응용하며, Transformer 모델에도 적용되었다.
'일상 > 컴퓨터' 카테고리의 다른 글
| [JavaScript 프로그래밍] 데이터 타입과 변수 (1) | 2024.10.09 |
|---|---|
| 텍스트 데이터 EDA와 Fake News Detection 모델 파이썬으로 구현해보기 2 (1) | 2024.09.29 |
| 트랜스포머 Transforemer와 어텐션 Attention (1) | 2024.09.07 |
| Fake News Detection 모델 파이썬으로 구현해보기 (7) | 2024.09.01 |
| [Tableau 태블로] 사용 편의를 높이는 그래프 확대 & 도구 설명 (0) | 2024.08.25 |