어텐션 (Attention)
어텐션 메커니즘은 자연어 처리 및 번역 모델에서 중요한 역할을 한다. 어텐션은 입력 벡터를 인코더에서 변환하고, 변환된 모든 벡터를 디코더로 전송하여 정보 손실 문제를 해결한다. 특히 RNN 기반의 모델들이 겪는 기울기 소실 문제(gradient vanishing problem)를 해결하는 데 주목할 만한 성과를 거뒀다. 어텐션 메커니즘은 입력 시퀀스의 모든 벡터를 전달하기 때문에 행렬 크기가 커지는 문제가 발생할 수 있다. 이를 해결하기 위해 소프트맥스(Softmax) 함수를 사용해 가중합을 구한 후, 그 값을 디코더에 전달하여 계산 비용을 줄인다.
디코더는 각 시점에서 중요한 정보를 찾아내고, 은닉 상태에서 중요한 벡터들에 집중한다. 구체적으로 소프트맥스 함수를 통해 각 벡터에 점수를 매기고, 이 점수를 은닉 상태 벡터들과 곱하여 중요한 정보만을 남긴다. 이 결과로 은닉 상태를 모두 더해 중요한 벡터들에 집중할 수 있게 된다. 이는 긴 시퀀스에서 중요한 부분에만 집중하게 하여 성능을 높이는 데 기여한다.
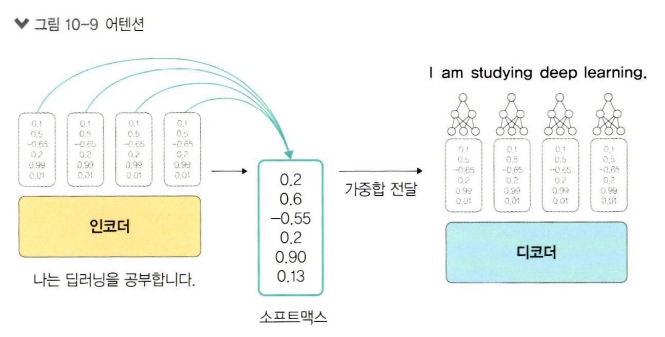
어텐션 메커니즘은 인코더에서 생성된 모든 은닉 상태를 디코더가 모두 유지하고 활용할 수 있게 한다. 디코더는 각 시점마다 인코더의 모든 은닉 상태와 현재 디코더의 은닉 상태를 바탕으로 컨텍스트 벡터를 계산하여, 그 시점에서 중요한 정보를 더 잘 학습할 수 있다. 이 과정을 통해 디코더는 특정 시점에서 가장 중요한 정보에 집중하게 되고, 문맥 상 중요한 부분에 더 많은 가중치를 부여한다.
어텐션 스코어 (Attention Score)

어텐션 스코어는 디코더가 특정 시점에서 단어를 예측하기 위해 인코더의 모든 은닉 상태 값과 디코더의 현재 은닉 상태가 얼마나 관련이 있는지를 판단하는 값이다. 어텐션 스코어는 디코더의 이전 시점 은닉 상태와 인코더의 모든 은닉 상태 값을 이용해 계산되며, 이를 통해 디코더는 현재 시점에서 어떤 정보를 더 많이 참조해야 하는지를 결정한다.

소프트맥스 함수를 통해 이 값을 확률로 변환하여 0과 1 사이의 값으로 표현되며, 이를 '시간 가중치'라고 부른다. 시간 가중치와 은닉 상태 값의 가중합을 통해 하나의 컨텍스트 벡터가 만들어진다.

컨텍스트 벡터는 디코더의 은닉 상태와 결합하여 최종 예측 결과를 만든다. 어텐션 메커니즘이 적용된 모델에서는 컨텍스트 벡터가 시점에 따라 변하는 반면, 어텐션이 없는 모델에서는 컨텍스트 벡터가 고정되어 있다. 이를 통해 어텐션 메커니즘을 활용한 모델이 더 많은 정보를 동적으로 활용할 수 있다.
트랜스포머 (Transformer)

트랜스포머는 2017년 "Attention is All You Need"라는 논문에서 처음 소개된 모델로, 어텐션 메커니즘을 최대한 활용하는 방법을 제시한다. 기존의 RNN(Recurrent Neural Network)이나 LSTM(Long Short-Term Memory)과 같은 순차적인 처리 모델 대신, 트랜스포머는 어텐션을 통해 병렬로 데이터를 처리한다는 점에서 혁신적이다. 트랜스포머는 인코더와 디코더로 구성되어 있으며, 각각이 여러 개의 셀프 어텐션(self-attention) 블록과 전방향 신경망(feed-forward neural network)으로 이루어져 있다. 논문에서는 이러한 인코더와 디코더를 6개씩 중첩한 구조를 제안했다.
트랜스포머는 RNN의 단점 중 하나인 순차적 처리의 비효율성을 극복하고, 병렬 처리를 가능하게 한다. 트랜스포머는 입력 시퀀스를 임베딩하고 포지셔널 인코딩을 통해 각 단어의 위치 정보를 반영한다. 이후 셀프 어텐션 메커니즘을 통해 시퀀스 내 각 단어 간의 관계를 계산하고, 이를 기반으로 각 단어의 중요성을 평가한다. 이를 통해 모델은 문장 내 단어들 간의 상관관계를 정확하게 학습할 수 있다.
인코더 블록 (Encoder Block)

인코더는 셀프 어텐션과 전방향 신경망으로 구성되어 있다. 각 단어는 임베딩 과정을 거쳐 포지셔널 인코딩이 적용된 후 셀프 어텐션 메커니즘을 통해 처리된다. 셀프 어텐션은 문장에서 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하여 단어 간의 관계를 파악한다. 이 과정을 통해 인코더는 문장 전체의 의미를 반영한 은닉 상태를 생성하며, 이 상태는 디코더로 전달된다.
디코더 블록 (Decoder Block)

디코더는 셀프 어텐션, 인코더-디코더 어텐션, 전방향 신경망으로 구성된다. 셀프 어텐션은 디코더가 이전에 생성된 출력과 관계를 학습하게 하고, 인코더-디코더 어텐션은 인코더에서 생성된 은닉 상태를 참조하여 입력 시퀀스와의 관계를 학습한다. 이로 인해 디코더는 입력과 출력 간의 상관관계를 파악하며, 올바른 출력을 생성할 수 있다.
Seq2Seq 모델

Seq2Seq(Sequence-to-Sequence) 모델은 입력 시퀀스에 대해 출력 시퀀스를 생성하는 모델이다. 주로 번역 작업과 같이 의미가 동일하지만 길이가 다를 수 있는 시퀀스를 생성하는 데 특화되어 있다. 이 모델은 인코더와 디코더 구조를 사용하여 입력 문장을 고정된 크기의 컨텍스트 벡터로 압축한 후, 이를 디코더로 전달하여 출력 시퀀스를 생성한다.
그러나 Seq2Seq 모델의 한계 중 하나는 긴 입력 시퀀스의 경우, 마지막 은닉 상태만 디코더로 전달되기 때문에 정보 손실이 발생할 수 있다는 점이다. 이를 '병목 문제(Bottleneck Problem)'라고 한다. 어텐션 메커니즘이 도입되면서 이 문제는 해결되었으며, 디코더는 인코더의 모든 은닉 상태를 참조하여 입력 시퀀스의 모든 정보를 활용할 수 있게 되었다.
Teacher Forcing

Teacher Forcing은 번역하려는 목표 단어(ground truth)를 디코더의 다음 입력으로 넣어주는 방법이다. 이 방법은 학습 속도를 높이고 초기 예측이 잘못되더라도 그 영향을 최소화할 수 있어 학습 초기에 안정적인 훈련이 가능하다. 그러나 실제 예측 단계에서는 이전 예측값을 사용해야 하기 때문에 학습과 테스트 간의 상황이 달라져 네트워크가 불안정해질 수 있다.
버트 (BERT)

버트(BERT, Bidirectional Encoder Representations from Transformers)는 구글이 2018년 11월에 공개한 양방향 자연어 처리 모델로, 트랜스포머의 인코더만을 사용하여 문장 내 단어 간의 관계를 양방향으로 학습한다. BERT는 기존의 단방향 자연어 처리 모델들이 문장을 처리할 때 앞에서부터 한 방향으로만 처리하는 한계를 극복하기 위해 등장하였다. BERT는 문장의 앞뒤 문맥을 동시에 학습하는 능력이 있어 자연어 처리 과제에서 뛰어난 성능을 보인다.
BERT는 방대한 양의 텍스트 데이터로 사전 훈련(pre-training)된 후, 다양한 자연어 처리 작업에서 미세 조정(fine-tuning)을 통해 활용된다. BERT는 문장 예측(Next Sentence Prediction, NSP)과 마스킹된 단어를 예측하는 작업(Masked Language Modeling, MLM)에 주로 사용된다. 입력 문장은 CLS 토큰으로 시작하고 SEP 토큰으로 끝난다. BERT는 이러한 입력을 토큰화하여 각각 고유한 ID를 부여하며, 필요한 경우 0으로 패딩(padding)한다.
BERT는 특히 트랜스포머 인코더 기반의 모델로, 전이 학습을 통해 다양한 NLP 작업에서 최적의 성능을 낸다.
'일상 > 컴퓨터' 카테고리의 다른 글
| 텍스트 데이터 EDA와 Fake News Detection 모델 파이썬으로 구현해보기 2 (1) | 2024.09.29 |
|---|---|
| ResNet 논문 리뷰 & Tensor Flow 이미지 분류 가이드 코드 분석 (0) | 2024.09.15 |
| Fake News Detection 모델 파이썬으로 구현해보기 (7) | 2024.09.01 |
| [Tableau 태블로] 사용 편의를 높이는 그래프 확대 & 도구 설명 (0) | 2024.08.25 |
| [논문리뷰] 이미지 생성 모델 Stable Diffusion (4) | 2024.08.18 |